
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Trouble shooting
- EarlyStopping
- AI
- ML
- json
- 머신러닝
- aof
- selenium
- nvidia-smi
- SMTP
- 그리디
- Logistic linear
- nvcc
- category_encoders
- 이것이 코딩 테스트다
- semi-project
- 인공지능
- Django
- Roc curve
- 파일입출력
- 트러블슈팅
- IOPub
- cuda
- auc
- beautifulsoup
- PYTHON
- 잡담
- 크롤링
- nvidia
- pandas
Archives
- Today
- Total
개발 블로그
[Python] 네이버 금융/ 거래량 상위 상승 종목 크롤링 본문

https://finance.naver.com/ 에서 당일 거래량 상위 종목중 상승한 종목만 크롤링하여 엑셀파일에 저장하는 프로그램입니다.
위에서 보이는 상승종목들 남선알미늄, 큐캐피탈, 이스트아이아홀딩스.... 들을 선별하여 DataFrame으로 만듭니다.
크롬개발자도구를 사용하여 종목들의 정보가 담긴 태그들을 찾아서 접근했습니다.
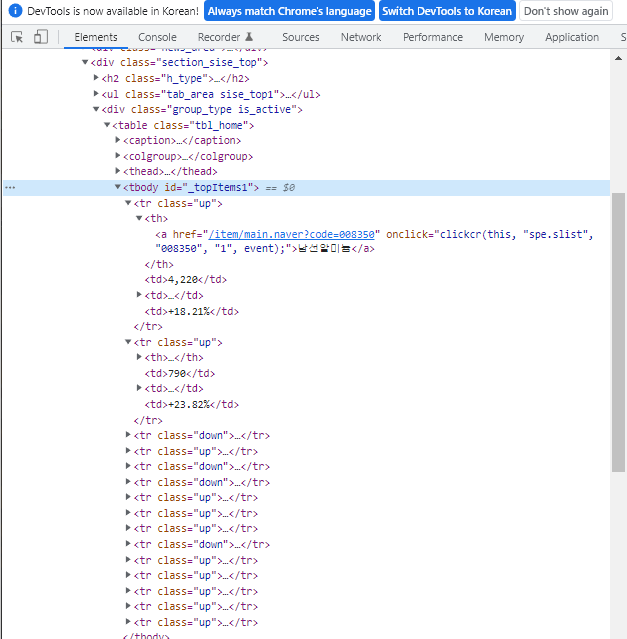
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'http://finance.naver.com'
res = requests.get(url).content
soup = BeautifulSoup(res, 'html.parser')
names = []
prices = []
delta_prices = []
delta_percents = []
items = soup.find('tbody',{'id':'_topItems1'})
item_rows = items.find_all('tr')
for item in item_rows:
if '상승' in item.find_all('td')[1].get_text(): # 상승한 종목만 리스트에 추가
names.append(item.find('th').get_text()) # 종목명
prices.append(item.find_all('td')[0].get_text()) # 현재가격
delta_prices.append(item.find_all('td')[1].get_text()[3:]) # 변동가격, [3:]으로 '상승' 단어를 빼고 가격만 포함
delta_percents.append(item.find_all('td')[2].get_text()) # 변동률
# for i, item in enumerate(delta_prices):
# if '상승' in item:
# delta_prices[i] = item.replace('상승','').strip()
# elif '하락' in item:
# delta_prices[i] = item.replace('하락','').strip()
df = pd.DataFrame({'가격':prices,'가격변동':delta_prices,'퍼센트':delta_percents},index=names)
print(df)
df.to_excel("오늘의 거래상위 상승 TOP종목.xlsx",encoding='utf-8')