
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 트러블슈팅
- 잡담
- beautifulsoup
- 이것이 코딩 테스트다
- pandas
- PYTHON
- Roc curve
- Trouble shooting
- selenium
- 그리디
- cuda
- auc
- IOPub
- Django
- category_encoders
- SMTP
- Logistic linear
- AI
- 파일입출력
- nvidia-smi
- semi-project
- EarlyStopping
- aof
- 인공지능
- json
- 크롤링
- nvidia
- nvcc
- ML
- 머신러닝
- Today
- Total
개발 블로그
[Toy_Project] Python 웹크롤링 - EPL순위 가져오기 본문

CODELION [심화]같이 푸는 Python 강의중에서 크롤링 강의를 듣고 응용해보기 위해서 네이버 스포츠 해외축구에서 EPL순위를 크롤링하는 프로그램을 만들어 봤습니다.
네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
목차>
목차
01 BeautifulSoup를 활용한 크롤링 시도
우선 배운대로 requests와 BeautifulSoup를 사용하려고 했습니다.

맨체스터 시티 FC라는 이름을 가져오기 위해 F12를 눌러 크롬개발자도구로 해당 부분의 태그를 찾았습니다.
(참고 : 크롬개발자도구 활용법)
태그는 span, 클래스는 name을 전달인자로 하여 findAll('span','name')함수를 사용하였습니다.
import requests
from bs4 import BeautifulSoup
url = "https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team"
response = requests.get(url)
html_text = response.text
soup = BeautifulSoup(html_text, 'html.parser')
teams = soup.findAll('span','name')
print(teams)그런데 여기서 문제가 발생했습니다. 실행시켜본 결과 아무런 값도 출력되지 않았습니다....

01_01 문제 해결 과정
결국 다른 여러함수들을 통해서 실험해봤으나 계속 원하는 값이 나오지 않았고 html_text를 html파일에 복사하여 전체 html을 뒤져보니 script태그 안에 팀명이 있는 부분을 발견했습니다.
""" html파일에 크롤링해온 html텍스트 write """
file_ = open("file.html",'w')
file_.write(html_text)
file_.close()
'script태그는 javascript파일에 쓰는거 아닌가? 그럼 html파일에 있는게 아니라 다른 파일에 링크되어 있는걸 가져와야되나?'라는 생각이 들었고 이에 대해 검색해본 결과 BeautifulSoup는 "자바스크립트로 동적으로 생성된 정보는 가져올 수 없다!"(출처:https://wikidocs.net/91474)라는 것을 확인하고 결국 동적생성된 정보를 크롤링 하기위해 selenium을 써야 된다는걸 깨달았습니다.
02 selenium을 활용한 크롤링
- selenium을 처음에 쓰려고 실행할 때 생긴 오류는 블로그 https://nanchachaa.tistory.com/18를 통해 해결했습니다.
- selenium예제는 블로그 https://ssamko.tistory.com/27를 참고했습니다.
- driver = webdriver.Chrome(executable_path="C:/Users/user/Downloads/chromedriver_win32/chromedriver.exe")에서 executable_path에는 반드시 본인의 chromedriver.exe가 깔려있는 경로를 사용해야합니다.
from bs4 import BeautifulSoup
from selenium import webdriver
from datetime import datetime
driver = webdriver.Chrome(executable_path="C:/Users/user/Downloads/chromedriver_win32/chromedriver.exe")
url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team'
driver.get(url)
print(datetime.today().strftime("%Y년 %m월 %d일의 EPL순위\n"))
soup = BeautifulSoup(driver.page_source, 'html.parser')
teams = soup.select("#wfootballTeamRecordBody > table > tbody > tr")
for team in teams:
team_ranking = team.select_one('td.num.best > div > strong')
team_name = team.select_one('td.align_l > div > span.name')
print(team_ranking, team_name.text)
""" copy selector 순위, 팀명 """
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.selected > div > span
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.num.best > div > strong02_01 문제점
selenium을 통해 코딩하는 도중에도 문제가 된 부분이 있었습니다.
순위를 가져오는데 1위 태그의 클래스<td class="num best">를 보고 td.num.best(클래스 값들은 .으로 구분합니다)로 가져오려고 했었습니다.
그런데 자꾸 1위의 값만 나왔고 .text를 통해 가져오려면 에러가 났습니다.

02_02 문제 해결
문제가 무엇인지 헤매다가 두번째 td태그를 보니 <td class"num ">인것을 확인했습니다.
결국 1등의 클래스만 num.best로 2가지 값을 갖고 나머지 팀의 순위는 클래스가num만 오는 것을 확인하고
td.num을 통해서 접근한 결과 모든 팀의 순위가 나왔습니다...!!!!(헤매다가 해결하니까 기뻤습니다^^)


from bs4 import BeautifulSoup
from selenium import webdriver
from datetime import datetime
driver = webdriver.Chrome(executable_path="C:/Users/user/Downloads/chromedriver_win32/chromedriver.exe")
url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team'
driver.get(url)
print(datetime.today().strftime("%Y년 %m월 %d일의 EPL순위\n"))
soup = BeautifulSoup(driver.page_source, 'html.parser')
teams = soup.select("#wfootballTeamRecordBody > table > tbody > tr")
for team in teams:
team_ranking = team.select_one('td.num > div > strong')
team_name = team.select_one('td.align_l > div > span.name')
print(team_ranking.text, team_name.text)
03 최종 코드
이러한 과정을 바탕으로 최종코드는 다음과 같습니다.
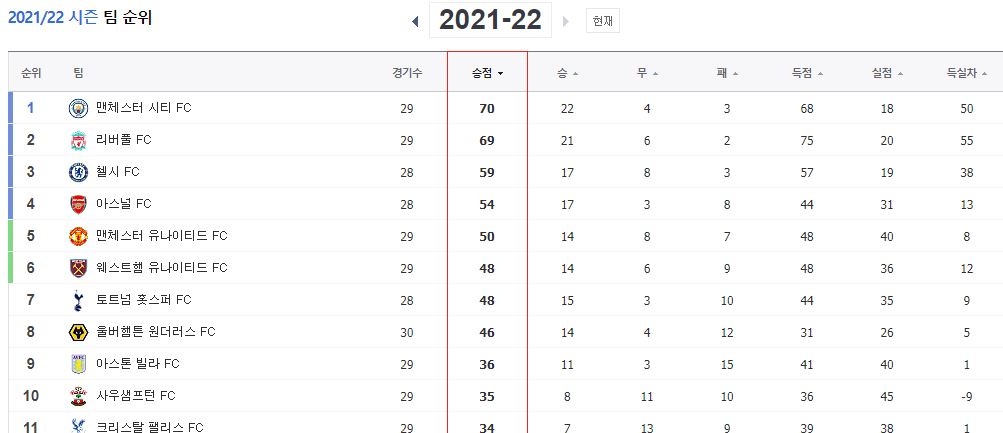
BeautifulSoup와 selenium을 사용하여 크롤링한 데이터 중에서 EPL순위, 팀명, 승점 데이터를 추출한 후 txt파일을 생성하여 저장하였습니다.
from bs4 import BeautifulSoup
from selenium import webdriver
from datetime import datetime
driver = webdriver.Chrome(executable_path="C:/Users/user/Downloads/chromedriver_win32/chromedriver.exe")
url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team'
driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
teams = soup.select("#wfootballTeamRecordBody > table > tbody > tr")
print(datetime.today().strftime("%Y년 %m월 %d일의 EPL순위\n"))
team_txt_file = open("teamranking.txt","w")
for team in teams:
team_ranking = team.select_one('td.num > div > strong')
team_name = team.select_one('td.align_l > div > span.name')
team_point = team.select_one('td.selected > div > span')
team_txt_file.write("순위 : {}등\n팀명 : {}\n승점 : {}점\n\n".format(team_ranking.text,team_name.text,team_point.text))
print("순위 : {}등\n팀명 : {}\n승점 : {}점\n".format(team_ranking.text, team_name.text, team_point.text))
team_txt_file.close()
""" copy selector 순위, 팀명, 승점 """
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.selected > div > span
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.num > div > strong
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.selected > div > spantxt파일에 정상적으로 출력된것을 확인할 수 있습니다.

2022-03-29 코드 수정
chromedriver를 다운받을 필요없이 코드에서 알아서 다운 받을 수 있게 변경.
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from datetime import datetime
""" chromedriver 설치 """
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team'
driver.get(url)
# 버전이 바뀌면서 chromedriver를 코드에서 실행해주는 걸로 변경.
# driver = webdriver.Chrome(executable_path="C:/Users/user/Downloads/chromedriver_win32/chromedriver.exe")
# url = 'https://sports.news.naver.com/wfootball/record/index?category=epl&year=2021&tab=team'
# driver.get(url)
soup = BeautifulSoup(driver.page_source, 'html.parser')
teams = soup.select("#wfootballTeamRecordBody > table > tbody > tr")
print(datetime.today().strftime("%Y년 %m월 %d일의 EPL순위\n"))
team_txt_file = open("teamranking.txt","w")
for team in teams:
team_ranking = team.select_one('td.num > div > strong')
team_name = team.select_one('td.align_l > div > span.name')
team_point = team.select_one('td.selected > div > span')
team_txt_file.write("순위 : {}등\n팀명 : {}\n승점 : {}점\n\n".format(team_ranking.text,team_name.text,team_point.text))
print("순위 : {}등\n팀명 : {}\n승점 : {}점\n".format(team_ranking.text, team_name.text, team_point.text))
team_txt_file.close()
""" copy selector 순위, 팀명, 승점 """
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.selected > div > span
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.num > div > strong
#wfootballTeamRecordBody > table > tbody > tr:nth-child(1) > td.selected > div > span
'Programming Language > Python' 카테고리의 다른 글
| [Python] 컨테이너(list, dict, tuple, set) (0) | 2022.03.22 |
|---|---|
| [Python] 기초 데이터 타입(int, float)과 문자열(string) (0) | 2022.03.21 |
| [CODELION 강의] [심화] 같이 푸는 PYTHON - 번역기, 메일 보내기 (0) | 2022.03.18 |
| [CODELION 강의] [심화] 같이 푸는 PYTHON - 오늘의 날씨 (0) | 2022.03.18 |
| [CODELION 강의] [심화] 같이 푸는 PYTHON - 크롤링 (0) | 2022.03.17 |



