
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- auc
- Django
- 이것이 코딩 테스트다
- json
- Logistic linear
- PYTHON
- 파일입출력
- EarlyStopping
- beautifulsoup
- nvcc
- semi-project
- 인공지능
- 잡담
- 그리디
- Trouble shooting
- IOPub
- aof
- 머신러닝
- Roc curve
- 크롤링
- nvidia-smi
- 트러블슈팅
- selenium
- nvidia
- SMTP
- ML
- pandas
- cuda
- category_encoders
- AI
- Today
- Total
개발 블로그
[Python] 컨테이너(list, dict, tuple, set) 본문

개인적으로 프로그래밍 언어 Python의 꽃이자 강점이라고 생각하는 컨테이너(list, dict, tuple, set)입니다.
C언어를 배울때 배열의 크기를 정하고, 메모리 할당(malloc)을 하고, 정렬함수도 직접 짜고 하던걸 생각하면 다시 한번 Python은 정말 편한 언어구나라는 생각을 합니다ㅎㅎ
(Python도 심화해서 사용하면 포인터와 자료형선언을 사용한다는 얘기를 들었던 것 같기도...?)
그럼 시작해보겠습니다!

01 리스트(list)
리스트는 [](대괄호)를 감싸서 나타냅니다.
아래와 같이 list()함수를 써서 변수를 리스트로 초기화 할 수 있지만, 이때는 반드시 iterable객체(반복 가능한 객체)를 넣어 주셔야 합니다!! (그냥 정수나 실수 자료형을 넣으면 오류가 뜹니다.)
x = [3, 1, 2, 4, 6] # 리스트의 생성
y = list('123')01_01 슬라이싱
리스트도 문자열자료형과 같이 인덱스가 존재하는 자료형이기 때문에 인덱스 번호로 리스트 요소에 접근 가능하며 슬라이싱이 가능합니다.
x = [3, 1, 2, 4, 6]
x[0] # 3
x[:3] # [3, 1, 2]
x[1:] # [1, 2, 4, 6]
x[-1] # 6주의※
슬라이싱으로 얻은 데이터의 자료형은 리스트이지만 인덱스로 얻은 한가지 요소의 자료형은
그 요소의 자료형입니다.
x = [3, 1, 2, 4, 6]
print(type(x[1:]))
print(type(x[-1]))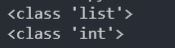
01_02 append()
리스트에 요소를 추가하려면 append()함수를 사용합니다. 이때 추가하는 자료형이 기존 리스트안의 요소와 같은 자료형이 아니여도 괜찮습니다. (C언어의 배열과는 엄청난 차이가 존재합니다...)
x = [3, 1, 2, 4, 6]
x.append("어머나")
x # [3, 1, 2, 4, 6, '어머나']01_03 pop()
pop()은 스택 자료구조에서 가장 늦게 추가된 데이터를 가장 먼저 제거하는 LIFO(Last In First Out)구조에서 따온 함수로 인덱스가 가장 큰 요소를 제거합니다.
"""기본적으로 리스트의 마지막 요소를 삭제하고 반환
(pop(n) -> index 기반으로 n번째 아이템을 삭제할 수도 있음)"""
x.pop() # '어머나'01_04 del
del 함수는 리스트의 앞에 위치하여 인덱스를 이용하여 해당 인덱스의 요소를 제거합니다.
del x[0]
x # [1, 2, 4, 6]01_05 remove()
remove()함수는 요소의 값을 이용하여 해당 값을 제거합니다.
요소의 값이 여러개 중복되어있는 경우 인덱스가 가장 낮은 요소를 제거합니다.
x.remove(4)
x # [1, 2, 6]01_06 sort()
sort()함수는 리스트.sort() 형식으로 사용하며 반환값이 없고 전달받은 리스트 자체를 정렬합니다. 따라서 다른 변수에 따로 대입을 해주지 않아도 되며 해서도 안됩니다.
만약 리스트를 정렬하여 다른 변수에 저장하고 싶다면 sorted()함수를 사용합니다.
기본값은 오름차순이며 내림차순으로 정렬하고 싶다면 sort(reverse = True)와 같이 해줍니다.
# sort() 리스트 정렬하기
z = [1, 2, 3, 4, 5, 6]
z.sort()
z # [1, 2, 3, 4, 5, 6]# sorted() 리스트 정렬하기
z = [1, 2, 3, 4, 5, 6]
sorted_z = sorted(z)
sorted_z # [1, 2, 3, 4, 5, 6]
02 딕셔너리(dict)
딕셔너리는 사전이라는 뜻을 가지고 있습니다. 사전에서 초성을 이용해서 원하는 단어를 찾듯이 딕셔너리는 key값을 가지고 이에 대응하는 value를 얻을 수 있습니다!
딕셔너리는 {}(중괄호)로 감싸서 표현하고 key와 value쌍은 : (쌍따옴표)를 통해 구분합니다.
cage = {'Cat' : '야옹', 'Dog' : '멍멍'} # {key:value, key:value, ...}
cage # {'Cat': '야옹', 'Dog': '멍멍'}02_01 get()
딕셔너리는 cage['Cat']과 같이 리스트에서 인덱스를 통해 요소에 접근하는 것처럼 [key]를 이용해서 value값을 얻습니다.
또 다른 방법으로 get()함수를 이용하여 value값을 얻을 수 있으며, 만약 딕셔너리에 해당하는 key값이 없다면 False일 때 나올 출력을 정할 수도 있어 유용하게 사용할 수 있습니다.
cage = {'Cat' : '야옹', 'Dog' : '멍멍'}
cage['Cat'] # '야옹'
cage.get('Tiger', '없는 동물입니다') # '없는 동물니다.'02_02 keys(), values(), items()
딕셔너리 뒤에 각각을 붙여서 출력해보면 key값, value값, (key,value)값이 각각의 딕셔너리 자료형으로 나오는 것을 확인할 수 있습니다.
리스트 자료형으로 사용해야 한다면 list()로 감싸주면 됩니다.
cage = {'Cat' : '야옹', 'Dog' : '멍멍'}
print(cage.keys())
print(cage.values())
print(cage.items())
03 튜플(tuple)
튜플은 DB에서는 릴레이션 테이블의 행, 인스턴스를 나타내는 용어로 쓰이기도 하고 컴퓨터를 배우다보면 여기저기서 자주 등장하는 것 같습니다.
Python에서 튜플은 한 번 초기화 되면 값과 크기를 수정할 수 없는 자료형을 뜻합니다.
리스트와 마찬가지로 인덱스로 튜플내의 요소들에 접근할 수는 있지만 수정할 수는 없습니다.
# 튜플이 사용되는 예시
def return_tuple(x, y):
print(x)
print(x, y)
return x, y
what = return_tuple(3, 4)
what # (3, 4)튜플은 위와 같이 함수의 리턴 값이 두개 이상 일 때, 이에 대해 한개의 변수로 리턴값을 대입받는 경우 튜플로 묶어줘서 한 개의 값으로 처리해줍니다. 리턴값이 세개면 요소가 세개인 튜플이 대입됩니다:)
04 집합(set)
집합자료형 set은 중복을 허용하지 않으며 set()함수를 이용하여 만들 수 있습니다. 집합자료형은 다음과 같은 특징이 있습니다.
- 중복을 허용하지 않는다.
- 순서가 없다(Unordered).
그리고 반환은 아래와 같이 {} 중괄호로 감싸져서 출력되는 것을 확인할 수 있습니다.
s1 = set([1,2,3])
s1 # {1, 2, 3}04_01 교집합, 합집합, 차집합
집합 자료형은 '집합'이므로 위와 같은 연산을 제공합니다.
합집합의 경우 두 집합간의 중복되는 값이 있는경우 중복을 제거하고 하나만 포함시킵니다.
이러한 특징때문에 중복을 제거해야 되는 상황에 집합 자료형을 유용하게 사용할 수 있습니다.
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
""" 교집합 연산 """
s1 & s2 # {4, 5, 6}
s1.intersection(s2) # {4, 5, 6}
""" 합집합 연산 """
s1 | s2 # {1, 2, 3, 4, 5, 6, 7, 8, 9}
s1.union(s2) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
""" 차집합 연산 """
s1 - s2 # {1, 2, 3}
s1.difference(s2) # {1, 2, 3}
'Programming Language > Python' 카테고리의 다른 글
| [Python ] Pandas DataFrame (0) | 2022.03.22 |
|---|---|
| [Python] 파일입출력 (0) | 2022.03.22 |
| [Python] 기초 데이터 타입(int, float)과 문자열(string) (0) | 2022.03.21 |
| [Toy_Project] Python 웹크롤링 - EPL순위 가져오기 (0) | 2022.03.21 |
| [CODELION 강의] [심화] 같이 푸는 PYTHON - 번역기, 메일 보내기 (0) | 2022.03.18 |



