
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 파일입출력
- 잡담
- Django
- IOPub
- ML
- 머신러닝
- pandas
- SMTP
- semi-project
- AI
- selenium
- 인공지능
- aof
- 트러블슈팅
- PYTHON
- Logistic linear
- auc
- 이것이 코딩 테스트다
- category_encoders
- nvcc
- Trouble shooting
- nvidia-smi
- 그리디
- json
- beautifulsoup
- 크롤링
- EarlyStopping
- nvidia
- Roc curve
- cuda
- Today
- Total
개발 블로그
[Python ] Pandas DataFrame 본문

오늘은 1강을 마치고, 2강을 시작했습니다!!
본격적으로 데이터를 다루기 시작하며 이제 numpy, pandas, matplotlib, seaborn를 배워나갈 것 같습니다.
오늘은 그중에서도 pandas에 대해서 알아봤습니다.
목차>
목차
pandas란?
pandas는 데이터 조작 및 분석을 위한 Python 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리 입니다 . 특히 숫자 테이블과 시계열 을 조작하기 위한 데이터 구조 와 연산을 제공합니다 .
출처 : Wiki Pandas
pandas.DataFrame은 2차원, 크기 변경이 가능한 테이블 형식 데이터입니다.
데이터 구조에는 레이블이 지정된 축(행과 열)도 포함됩니다. Series객체를 위한 dict-like 컨테이너로 생각할 수도 있습니다.
(출처 : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html)
pandas.DataFrame() # 2차원 리스트
pandas.Series() # key 값이 있는 1차원 리스트import numpy as np
import pandas as pd
import seaborn as sns
df = pd.read_excel('animals.xlsx') # read_excel() : 엑셀파일을 읽어서 df객체에 대입합니다.
df
01_01 head(), tail()
head()함수는 테이블의 상위 5개 행을 반환합니다.
매개변수를 입력하면 그만큼의 상위 행의 개수를 반환합니다.
df.head()
h1 = df.head() # 다른 변수에 대입도 가능

tail()함수는 테이블의 하위 5개 행을 반환합니다.
매개변수를 입력하면 그만큼의 하위 행의 개수를 반환합니다.
df.tail()

01_02 describe()
데이터셋의 수치형 컬럼별 주요 통계량들을 요약해서 보여줍니다.
df.describe() # 각 열의 기술 통계량 (Descriptive Statistics)
# Count : 컬럼별 총 데이터수
# mean / std : 컬럼별 데이터의 평균/ 표준편차
# min / max : 컬럼별 데이터 최소값 / 최대값
# 25% / 50% / 75% : 사분위수의 각 지점으로, 분포를 반영해 평균을 보완합니다
01_03 info()
데이터셋에 존재하는 컬럼명과 컬럼별 결측치, 컬럼별 데이터타입을 확인할 때 사용합니다.

※Note : 결측치(missing data)를 다루는 대표적인 방법
- 랜덤하게 채워넣기
- 주변 (행의) 값들로 채워넣기
- 열의 대푯값을 계산해서 채워넣기 (mean, median중윗값)
- 전체 행들을 그룹으로 묶어낸 후 그룹 내 해당 열의 대푯값으로 채워넣기
- 나머지 열들로 머신러닝 예측모델을 만든 후 해당 열의 값을 예측해 채워넣기 - 특정 기준 비율 이상으로 빠져있을 시 해당 열 삭제
02 DataFrame에서 일부 "행" 꺼내기
DataFrame에서 하나의 행 또는 열은 Series라는 객체자료형을 가집니다.
행의 인덱스명은 기본적으로 0부터 시작합니다.
type(df['hair'])
type(df.loc[3])
# 위의 둘 다 결과값으로 pandas.core.series.Series- 1차원 배열과 같은 자료구조, index가 같이 출력
- DataFrame의 한 개의 column에 해당하는 데이터의 모음 object, 즉, column vector를 표현
- 정렬되지 않은 값
02_01 loc[ ]
loc는 location의 약자로 인덱스명 통해 행을 출력합니다.
df.loc[3] # pandas.core.series.Series
df.loc[[3]] # pandas.core.frame.DataFrame- df.loc[3]은 1차원 배열로 Series자료형입니다.
- df.loc[[3]]처럼 배열형태를 입력하면 2차원 DataFrame 자료형이 리턴됩니다.
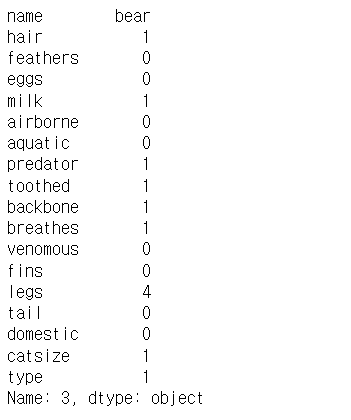

여러 개의 행을 꺼내기
df.loc[3, 6, 8] # Key들을 list로 줘야 합니다.
범위로 지정해 꺼내기 & 열까지 범위 지정하기
이와 비슷한 방법으로 iloc이 뒤에 나옵니다.
df.loc[3:6, 'name':'feathers'] # 뒤까지 모두 포함하는 범위임을 유의, index가 아니라 name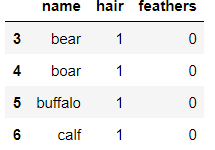
02_02 str.contains()
선택한 열의 문자열에 특정 문자열이 포함되어있는지를 체크합니다.
특정 문자열이 들어있는 데이터의 개수를 셀 때( sum() ) 사용가능합니다
df["name"].str.contains("ar")
sum(df["name"].str.contains("ar"))
※선택한 열의 문자열에 특정 문자열이 포함된 열들만 선택하고자 할 경우
df["name"].str.contains("ar") 을 통해 "ar"이 포함된 행들을 추출하고,
[ : ] 슬라이싱으로 행들의 모든 열을 리턴합니다.
df.loc[df["name"].str.contains("ar"), :]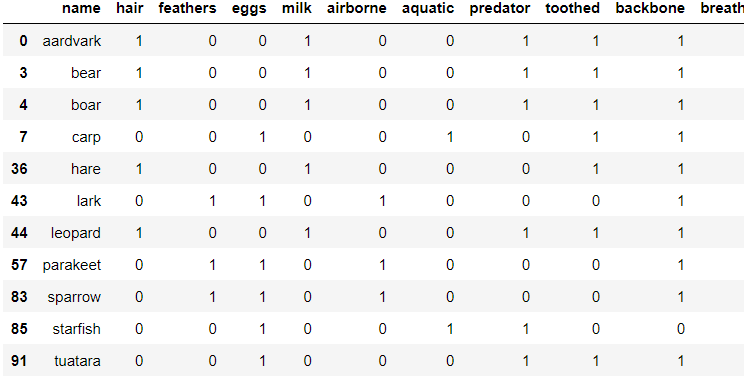
02_03 iloc[ ]
index location의 약자로 열을 name이 아니라 번호로 지정하고 싶다면 사용합니다.
다음과 같이 열의 범위를 구하기 위해 속성명을 사용하는 것이 아니라 열의 인덱스번호를 활용합니다.
df.iloc[3:6, 0:3]
03 DataFrame에서 일부 "열" 꺼내기
pandasDataFrame에서 원하는 열에 접근하는 것은 Python의 딕셔너리에서 key값을 통해 value에 접근하는 것과 비슷합니다.
dr['name']과 같이 열의 속성명을 key값으로 하고 이에 대응하는 값들이 리턴됩니다.
df['name']
# 둘 다 같은 값을 리턴합니다
df['name'][0] # 열 Series 기준으로는 행의 이름이 key 값
df.loc[0]['name'] # 행 Series 기준으로는 열의 이름이 key 값여러개의 열 출력하기
이때 주의해야 할점은 반드시 [ ]로 열의 속성명들을 감싸서 전달해줘야 합니다.
df[['name', 'hair', 'feathers']]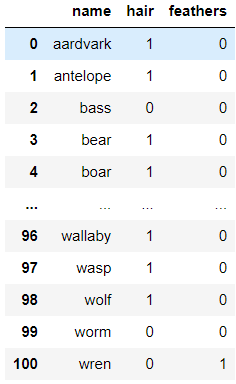
04 DataFrame 다루기 with Advanced functions
기존 df에서 일부 열만 떼어네서 새로운 df를 만들고 새로운 열을 추가하는 것을 해보겠습니다.
우선 다음과 같은 열을 따로df_new에 대입해주겠습니다.
df_new=df[['name', 'hair', 'feathers', 'eggs', 'milk', 'type']]이어서 'hair'열의 값들을 1씩 더해서 새로운 new_hair_temp 열에 대입해 보겠습니다.
new_hair = []
for num in df_new['hair']:
new_hair.append(num + 1) # 값에 1을 더해주고 다음행으로 넘어갑니다.
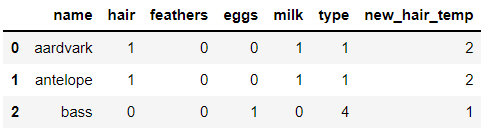
df_new['new_hair_temp'] = new_hair # 'new_hair_temp'열을 만들고 new_hair리스트를 대입합니다.
df_new.head(3) # 상위 3개의 값을 출력합니다.다음 출력 결과를 보면 new_hair_temp열이 생기고 hair의 값에서 1이 더해진 것을 볼 수 있습니다:)
이번엔 apply함수와 lambda함수를 사용하여 훨씬 간결하게 위와 같은 결과를 만들어 보겠습니다.
(비교를 위하여 이번에는 열의 이름을 'new_hair'로 만들었습니다.)
df_new['new_hair'] = df_new['hair'].apply(lambda x : x+1)
df_new.head(3)단 두줄로 5줄의 코드를 대신할 수 있게되었습니다!!

04_01 pivot_table
pivot_table은 새로운 테이블에서 새로운 기준으로 집계하는 것을 의미합니다.
'type'열을 index로 하는 새로운 df객체를 만들어 보겠습니다.
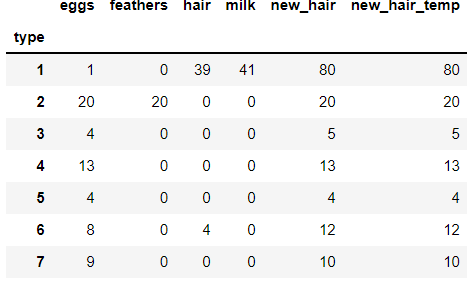
pivot_df = pd.pivot_table(df_new, index='type', aggfunc=np.sum)
pivot_df출력을 보면 7가지 type을 기준으로 테이블이 새롭게 생성되었고 aggfunc=np.sum 에 따라서 타입별 총합이 출력된것을 확인할 수 있습니다.
pivot_table의 행과 열 삭제하기
열을 삭제할때는 del를 사용하고 객체의 열 속성명을 전달해주면 됩니다.
del pivot_df['new_hair']
pivot_df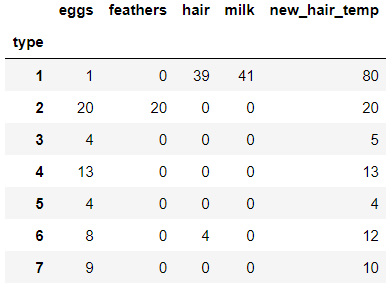
행을 삭제 할때는 drop() 함수를 사용해야 합니다.
DB테이블을 삭제하는 DROP연산이 떠오르네요!
pivot_df = pivot_df.drop([3]) # Database 에서 data point 를 drop!
pivot_df04_02 열 이름 바꾸기
rename() 함수를 사용하여 열 이름을 바꿀 수 있습니다.
columns파라미터에 딕셔너리 형식으로 바꿀 열의 이름과 바꿀 이름을 전달해줍니다.inplace파라미터를 이용하여rename함수를 적용하는 DataFrame객체 덮어쓰기 여부를 선택할 수 있습니다.
만약inplace=False로 한다면 바뀐열의 이름을 확인하기 위해 다른 객체에 리턴값을 대입해 줘야 합니다.
pivot_df.rename(columns = {'eggs':'산란', 'feathers':'깃털'}, inplace=True) # inplace 옵션 == 덮어쓰기 여부
pivot_df.head()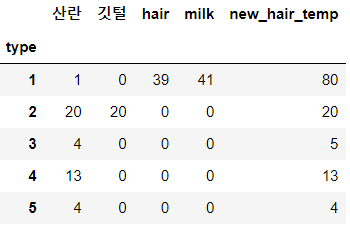
04_03 열을 기준으로 정렬하기
sort\_values함수를 사용하여 정렬할 수 있습니다.
- by파라미터는 정렬의 기준이 되는 열의 속성명을 대입합니다.
- ascending파라미터를 True로 하면 오름차순, False는 내림차순
pivot_df.sort_values(by='산란',ascending=True ,inplace=True) # 내용(value)을 기준으로 정렬(sort), inplace=True : 덮어쓰기
pivot_df.head()
04_04 얕은 복사와 깊은 복사
얕은 복사(shallow copy)와 깊은 복사(deep copy)의 차이는 복사본을 받은 변수를 변경하였을때 원본 변수의 값에 영향을 주는냐 안주느냐의 차이입니다.
이러한 차이는 두 변수가 가리키는 값의 주소가 같은값이냐 다른값이냐에 따라 나뉩니다.
- 대입연산자 '='는 얕은 복사
- copy()함수를 사용하여 깊은 복사
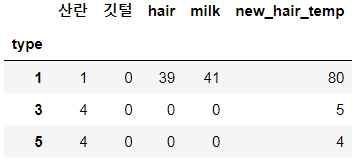
pivot_df_2 = pivot_df # shallow copy 같은 주소를 가리킨다
pivot_df_3 = pivot_df.copy() # deep=True, deep copy 다른 주소에 만든다
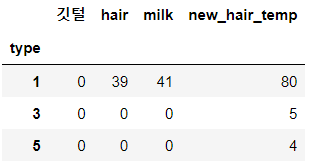
del pivot_df['산란']
>>> pivot_df_2.head(3)
>>> pivot_df_3.head(3)아래의 출력을 보면 '산란'속성 열의 유무를 확인 할 수 있습니다.
'Programming Language > Python' 카테고리의 다른 글
| [Python] 데이터 시각화 (지도/ Folium, GeoJSON) (0) | 2022.03.24 |
|---|---|
| [Python] pandas, seaborn 실습 (0) | 2022.03.23 |
| [Python] 파일입출력 (0) | 2022.03.22 |
| [Python] 컨테이너(list, dict, tuple, set) (0) | 2022.03.22 |
| [Python] 기초 데이터 타입(int, float)과 문자열(string) (0) | 2022.03.21 |



