
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- beautifulsoup
- IOPub
- 잡담
- 파일입출력
- 이것이 코딩 테스트다
- Roc curve
- nvidia-smi
- aof
- 인공지능
- Trouble shooting
- selenium
- Logistic linear
- PYTHON
- auc
- nvcc
- 머신러닝
- AI
- pandas
- category_encoders
- EarlyStopping
- cuda
- Django
- semi-project
- SMTP
- ML
- json
- 크롤링
- nvidia
- 트러블슈팅
- 그리디
- Today
- Total
개발 블로그
[Python] pandas, seaborn 실습 본문

저번 시간에는 pandas Dataframe에 대해 알아봤었습니다.
이번에는 공공데이터포털의 관서별 5대범죄 발생 및 검거 엑셀파일 데이터를 가져와서 실습을 했습니다.
이번 시간에는 seaborn라이브러리로 시각화까지 진행했습니다.
이걸 어떻게 정리해서 올려야 하나 고민이 되는데,,, 일단 수업했던 흐름에 맞춰서 설명을 덧붙여 보겠습니다:)
목차>
목차
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # rc == run configure(configuration file)from matplotlib import font_manager, rc # rc == run configure(configuration file)
이부분은 시각화 할 때 한글깨짐을 해결하기 위한 부분입니다.
01 데이터 입력 및 데이터 전처리
먼저 엑셀 파일을 read_excel()함수로 불러오고 df에 대입해줬습니다.
# 서울시 관서별 5대 범죄 발생 & 검거 현황 @ data.go.kr
df = pd.read_excel('관서별 5대범죄 발생 및 검거.xlsx') # 엑셀 파일 읽기
df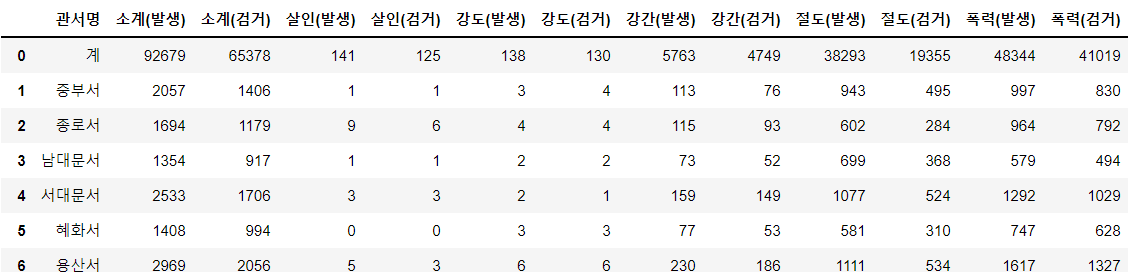
위의 DataFrame을 보시면 첫번째 행에 '계'라는 총합계 행이 있습니다. 이러한 데이터를 제외시키고 싶을 때가 있을 수 있겠죠??
df[ ]에 조건문을 사용하여 해당 행을 제외시키고 출력값을 볼 수 있습니다.
만약 출력 값만 바꾸는게 아니라 DataFrame에서 완전히 제거 하고 싶다면 drop()함수를 사용합니다.
df[df['관서명']!='계']
02 경찰서를 구별로 정리하기
경찰청의 소속 구가 겹치는 부분이 있습니다. (중부서, 남대문서 -> 중구)
때문에 구가 겹칠 경우 경찰청의 데이터를 합쳐줍니다. 우선 경찰청별 구이름의 dictionary 변수를 만들어 줍니다.
# 서울시 경찰청의 소속 구 @ https://goo.gl/MQSqXX
police_to_gu = {'서대문서': '서대문구', '수서서': '강남구', '강서서': '강서구', '서초서': '서초구',
'서부서': '은평구', '중부서': '중구', '종로서': '종로구', '남대문서': '중구',
'혜화서': '종로구', '용산서': '용산구', '성북서': '성북구', '동대문서': '동대문구',
'마포서': '마포구', '영등포서': '영등포구', '성동서': '성동구', '동작서': '동작구',
'광진서': '광진구', '강북서': '강북구', '금천서': '금천구', '중랑서': '중랑구',
'강남서': '강남구', '관악서': '관악구', '강동서': '강동구', '종암서': '성북구',
'구로서': '구로구', '양천서': '양천구', '송파서': '송파구', '노원서': '노원구',
'방배서': '서초구', '은평서': '은평구', '도봉서': '도봉구'}이어서 관서명을 딕셔너리의 key값으로 하여 얻은 value(구이름)를 '구별'속성을 만들어서 대입했습니다.
이때 apply()함수와 lambda함수를 사용합니다.
- dict[칼럼명].apply(칼럼 내 데이터마다 적용할 함수)
- dict.get(key, default=None)는 value 를 return, 만약 key가 없을 경우 default=None값을 반환하거나 설정한 값을 return
df['구별'] = df['관서명'].apply(lambda x: police_to_gu.get(x, '구 없음'))
df.head()보시면 '구별' 속성이 생기고 딕셔너리에 없는 '계'는 '구 없음'으로 표시됐습니다.

02_01 '구별'을 인덱스로 하는 테이블 만들기
pivot_table()함수를 사용해서 인덱스를 바꿉니다.
# pivot_table 기본형
pd.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
observed=False,
) -> 'DataFrame'gu_df = pd.pivot_table(df, index='구별', aggfunc=np.sum)
gu_df
drop()함수를 사용하여 구 없음 행을 삭제했습니다.
gu_df = gu_df.drop(['구 없음'])
gu_df02_02 검거율 계산
- 검거율 = 검거 / 범죄수 * 100
위의 식을 통해서 각각의 검거율을 구하고 검거율 속성에 검거율값들을 넣었습니다.
gu_df['검거율'] = gu_df['검거']/gu_df['발생'] * 100그리고del함수를 사용하여 검거속성들과 소계속성을 지웠습니다.
del gu_df['검거']
del gu_df['소계']
02_03 masking
검거율이 100이 넘는 이유는 발생건수는 2016년만의 값이고, 그 전에 발생한 범죄에 대한 검거가 2016에 이뤄지면 검거수에 반영됐기 때문입니다. 그래서 이에 대한 값을 보정합니다.
masking이란 데이터의 일부를 가리고 원하는 값만 얻기 위해서 사용합니다.
(1) for문, iterrows() 사용
- iterrows() : DataFrame객체 행(rows)의 (index, Series)데이터쌍을 반환합니다.
- at[행, 열] : 행열쌍의 한가지 값을 반환합니다.
columns = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
gu_df_rate = gu_df[columns]
for row_index, row in gu_df_rate.iterrows():
for column in columns:
if row[column] > 100:
gu_df.at[row_index, column] = 100 # 100이 넘는 검거율은 100으로 바꿔줌
gu_df.head(10)(2) masking 사용
gu_df[ gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100 ] = 100
gu_df.head(10)masking 할 때 사용하는 논리연산자들
- and연산자 : &
- or연산자 : | (shift + \)
- not연산자 : ~
02_05결측치 채우기 fillna()
fillna(채울값)함수를 이용하여 '살인검거율' 열의 결측치를 100으로 채워줬습니다. (결측치가 채워진 열을 기존 열에 덮어써줘야 하는 것에 유의)
gu_df['살인검거율'] = gu_df['살인검거율'].fillna(100)02_06 join( )
인구데이터가 있는 csv파일을 불러옵니다.
'구별' index 를 기준으로 merge를 할 것이므로, index를 '구별'로 세팅해줬습니다.
popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8', index_col='구별')
popul_df.head()
# 아래와 같이 먼저 read_csv()로 읽어들이고 .set_index()를 적용할 수도 있습니다.
# popul_df = pd.read_csv('pop_kor.csv', encoding='utf-8').set_index('구별')합병은join()함수를 사용합니다.
# join() 함수의 기본형
join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False) -> 'DataFrame'gu_df = gu_df.join(popul_df) # df1.join(df2) : df1 의 index를 기준으로 df2 의 index 중 매칭되는 값을 매김
gu_df.head()03 데이터 시각화
※ 그래프 한글패치
font_name = font_manager.FontProperties(fname="폰트주소").get_name()
rc('font', family = font_name)
sns.heatmap(gu_df[['강간', '강도', '살인', '절도', '폭력']])
그래프를 보면 강도, 살인의 수치가 다 검은색으로 나옵니다.
정규화(Feature Nomalization)
# 5대 범죄별 수치를 해당 범죄별 최대값으로 나눠줌
weight_col = gu_df[['강간', '강도', '살인', '절도', '폭력']].max()
crime_count_norm = gu_df[['강간', '강도', '살인', '절도', '폭력']] / weight_colsns.heatmap(crime_count_norm.sort_values(by='살인', ascending=False))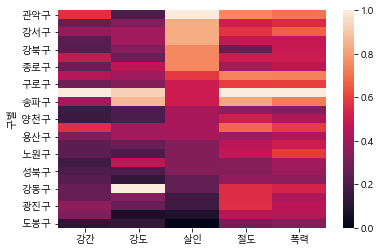
전체 figure 사이즈 조정
- plt.figure(figsize = (10, 10))
- dpi(dot per inch) 파라미터를 설정하면 해상도 조절 가능
heatmap( )
- annot : 셀 내에 수치 입력 여부
- fmt : 셀 내 입력될 수치의 format (f == float)
- linewidths : 셀 간 이격거리 (하얀 부분, 내부 테두리)
- cmap : matplotlib colormap @ https://goo.gl/YWpBES
sns.heatmap(crime_count_norm.sort_values(by='살인', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(살인발생으로 정렬) - 각 항목별 최대값으로 나눠 정규화')
plt.show()
03_ 01 인구수 대비 구별 살인 발생 순위
범죄수DataFrame.div(인구수DataFrame, axis = 0)
- axis = 0 : 열 방향 연산(많은 함수에서 Default)
- axis = 1 : 행 방향 연산
plt.figure(figsize = (10,10))
sns.heatmap(crime_ratio.sort_values(by='살인', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(살인발생으로 정렬) - 각 항목을 정규화한 후 인구로 나눔')
plt.show()
03_02 인구 수 대비 구별 5대범죄 발생 수치 평균
crime_ratio['전체발생비율'] = crime_ratio.mean(axis=1)03_03 인구 수 대비 5대범죄 발생 수치 평균 기준 구별 순위 비교
plt.figure(figsize = (10,10))
sns.heatmap(crime_ratio.sort_values(by='전체발생비율', ascending=False), annot=True, fmt='f', linewidths=.5, cmap='Reds')
plt.title('범죄 발생(전체발생비율로 정렬) - 각 항목을 정규화한 후 인구로 나눔')
plt.show()
'Programming Language > Python' 카테고리의 다른 글
| [Python] googlemaps를 사용해서 각 경찰서의 위도, 경도 정보를 얻기 (0) | 2022.03.24 |
|---|---|
| [Python] 데이터 시각화 (지도/ Folium, GeoJSON) (0) | 2022.03.24 |
| [Python ] Pandas DataFrame (0) | 2022.03.22 |
| [Python] 파일입출력 (0) | 2022.03.22 |
| [Python] 컨테이너(list, dict, tuple, set) (0) | 2022.03.22 |



