
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- ML
- semi-project
- json
- 인공지능
- PYTHON
- nvidia-smi
- aof
- 잡담
- nvidia
- IOPub
- Roc curve
- selenium
- pandas
- AI
- 이것이 코딩 테스트다
- Logistic linear
- 파일입출력
- 크롤링
- nvcc
- EarlyStopping
- Django
- Trouble shooting
- 트러블슈팅
- category_encoders
- beautifulsoup
- cuda
- SMTP
- 머신러닝
- auc
- 그리디
Archives
- Today
- Total
개발 블로그
[Python] konlpy 한국어 텍스트 분석과 시각화 본문

01 크롤링 데이터 전처리
이전에 웹 스크래핑(1)에서 만들었던 엑셀파일을 대상으로 분석을 하겠습니다.
import numpy as np
import pandas as pd
df = pd.read_excel('result_220202_1834.xlsx')
df.head(3)
Article속성에 해당하는 기사의 본문 내용을 리스트로 만들어 줍니다.
그리고 join함수로 리스트를 하나의 문자열로 만들고 1000번째 자리의 문자까지만 남깁니다.
articles = df['Article'].tolist()
print(len(articles)) # 30
articles = ' '.join(articles)
articles = articles[:1000]
print(articles)
02 단어 정규화, 어근화, 품사 태깅
konlpy에서 Okt라는 모듈을 import해주고 객체 변수를 정의합니다.
pos( )함수
- tokenize( 토큰화, 형태소로 나눈다 )
- norm파라미터는 정규화(nomalization), stem파라미터는 어근화(stemming) 여부를 조작합니다.
- 마지막으로 품사 태깅을 해줍니다.
from konlpy.tag import Okt
tokenizer = Okt()
raw_pos_tagged = tokenizer.pos(articles, norm=True, stem=True) # POS Tagging
print(raw_pos_tagged)출력 결과를 보면 튜플 쌍으로 단어와 품사가 묶여서 리스트가 형성된것을 볼 수 있습니다.

03 단어 등장 빈도 카운팅
우선 불용어들을 제거해 줍니다. (임의로 설정해줬습니다.)
그리고 한 글자로 이루어진 단어도 제거합니다.
del_list = ['를', '이', '은', '는', '있다', '하다', '에']
word_cleaned = []
for word in raw_pos_tagged:
if not word[1] in ["Josa", "Eomi", "Punctuation", "Foreign"]: # Foreign == ”, “ 와 같이 제외되어야할 항목들
if (len(word[0]) != 1) & (word[0] not in del_list): # 한 글자로 이뤄진 단어들을 제외 & 원치 않는 단어들을 제외, 대신 "안, 못"같은 것까지 같이 지워져서 긍정,부정을 파악해야 되는경우는 제외하지 않는다.
word_cleaned.append(word[0])
print(word_cleaned)
Counter( )메소드를 사용해 주고 dict( )로 캐스팅해줍니다.
result = Counter(word_cleaned)
word_dic = dict(result)
print(word_dic)
sorted( ) 함수로 정렬해줍니다. key파라미터에 단어의 개수를 전달인자로 하는 lambda함수를 통해 정렬해줍니다.
- word_dic.imtes( )를 통해 딕셔너리의 key, value쌍을 튜플로 받습니다.
- 이 튜플에서 lambda함수에 output값으로 x[1]을 설정하여 단어의 개수를 key파라미터의 값으로 합니다.
sorted_word_dic = sorted(word_dic.items(), key=lambda x:x[1], reverse=True)
print(sorted_word_dic)
04 단어 등장 빈도 시각화
04_01 실선그래프
matplotlib을 이용해 그래프를 그려줬습니다.
nltk는 다음 글을 참고하세요 -> [Python] 웹 크롤링 & 자연어 처리 (2)
import nltk
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
# 그래프에 한글 폰트 설정
font_name = matplotlib.font_manager.FontProperties(fname="C:/Windows/Fonts/malgun.ttf").get_name() # NanumGothic.otf
matplotlib.rc('font', family=font_name)
word_counted = nltk.Text(word_cleaned)
plt.figure(figsize=(15,7))
word_counted.plot(50)
04_02 막대그래프
FreqDist 클래스는 문서에 사용된 단어(토큰)의 사용빈도 정보를 담는 클래스입니다.
(참고 : NLTK 자연어 처리 패키지)
word_frequency = nltk.FreqDist(word_cleaned)
df = pd.DataFrame(list(word_frequency.values()), word_frequency.keys())
result = df.sort_values([0], ascending = False)
result = result[:50]
result.plot(kind='bar', legend=False, figsize=(15,5))
plt.show()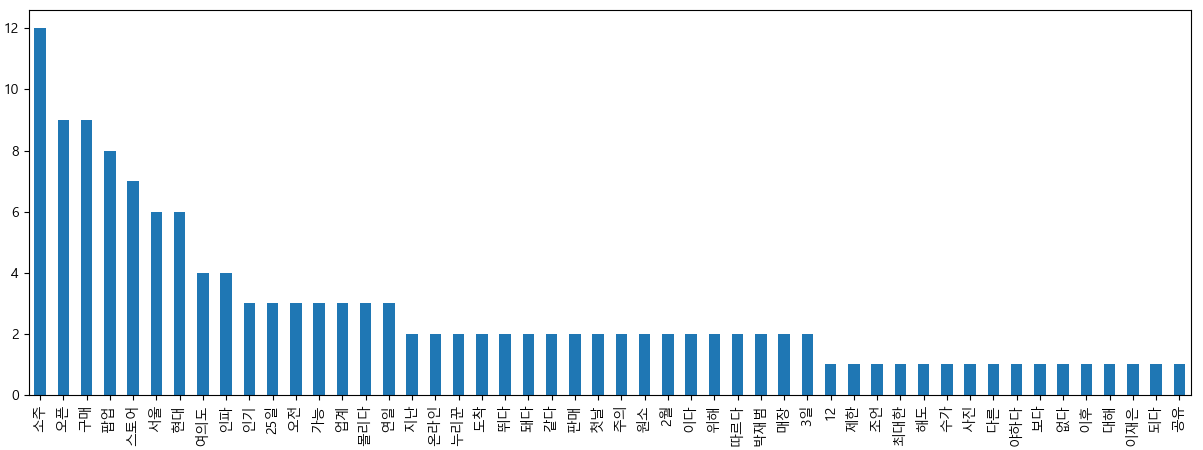
'Programming Language > Python' 카테고리의 다른 글
| [Python] Selenium translation 셀레늄으로 번역기 돌리기 (0) | 2022.03.29 |
|---|---|
| [Python] Wordcloud 만들기 (0) | 2022.03.29 |
| [Python] 웹 스크래핑 (1) (0) | 2022.03.29 |
| [Python] TF-IDF, Cosine Similarity (0) | 2022.03.28 |
| [Python] 웹 크롤링 & 자연어 처리 (2) (0) | 2022.03.25 |
'Programming Language/Python' Related Articles
more




Comments