
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- cuda
- AI
- 파일입출력
- category_encoders
- 잡담
- semi-project
- EarlyStopping
- Logistic linear
- aof
- 트러블슈팅
- auc
- ML
- 인공지능
- Roc curve
- pandas
- 머신러닝
- nvcc
- json
- selenium
- nvidia
- 그리디
- nvidia-smi
- Trouble shooting
- Django
- IOPub
- beautifulsoup
- 크롤링
- 이것이 코딩 테스트다
- PYTHON
- SMTP
- Today
- Total
개발 블로그
[Python] 웹 스크래핑 (1) 본문

목차>
목차
웹 스크래핑을 위한 라이브러리 import
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
import re
01 '원소주' 뉴스기사 스크래핑 시작
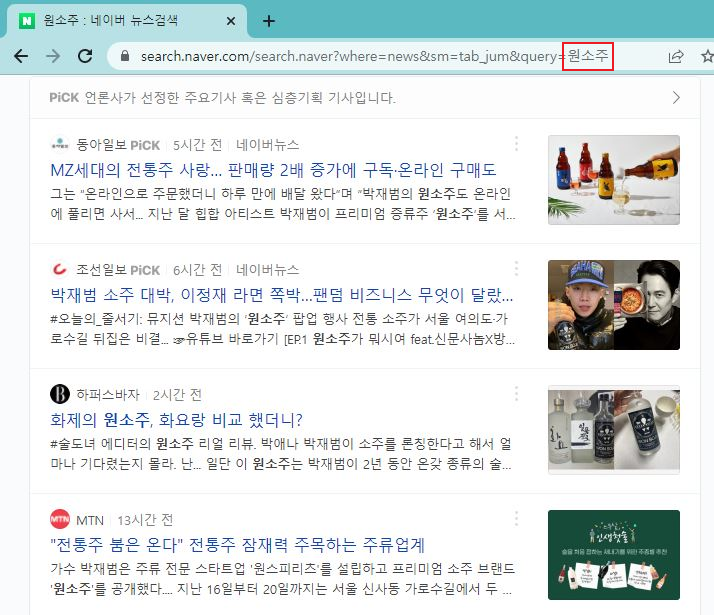
원소주를 검색하고 뉴스탭을 보면 query라는 파라미터에 '원소주'를 전달인자로 받는걸 볼 수 있습니다.
requests.get(url).content로 응답을 받고, 이를 BeautifulSoup객체로 변환합니다.
※ 주소를 복사할 때 그냥 복사해서 붙여넣기 하면 url을 파악하기 힘들게 깨질 수 있습니다.
따라서 다음과 같이 복사합니다.
url 제일 앞에 커서가 오도록 클릭 -> 스페이스 한칸 띄우기 ->Shift + ↓로 전체선택 -> Ctrl + C
query = '원소주'
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=' + query
response = requests.get(url).content
soup_response = BeautifulSoup(response,'html.parser')
그리고 뉴스기사의 제목들에 접근하기 위해 크롬 개발자 도구(F12)로 html코드를 분석해 보겠습니다.
제목 부분의 태그는 <a>태그이며 class="news_tit"인 것을 확인 할 수 있습니다.
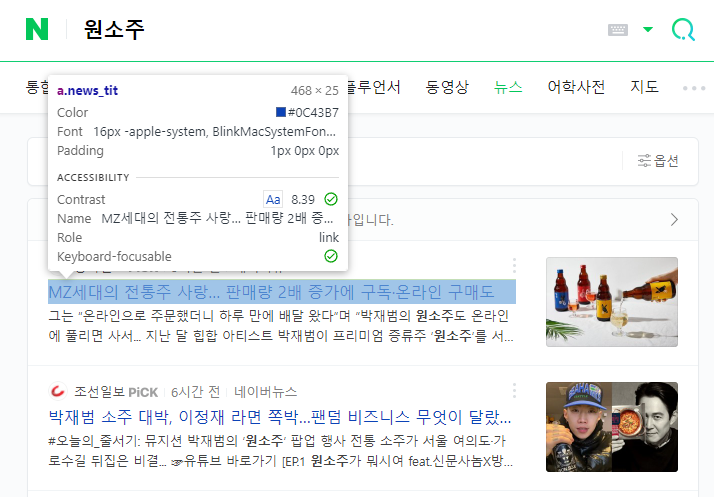
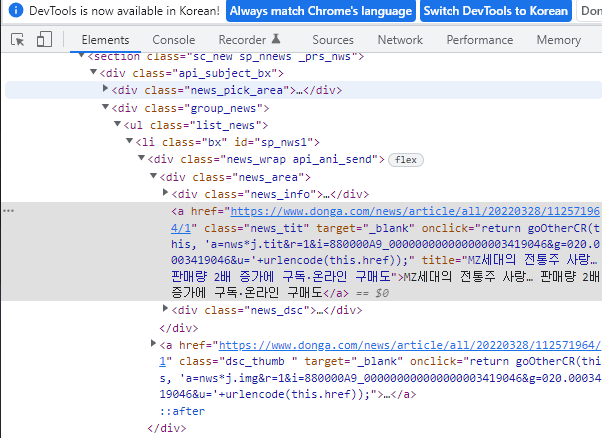
다음과 같이 find_all( ) 함수에 적용하고 얻은 내용을 확인해보겠습니다.
news_subject = soup_response.find_all('a',{'class','news_tit'})
for sub in news_subject:
print(sub.get_text())출력 결과를 보니 제목만 잘 출력됐습니다.

이제 각 뉴스의 url을 알아내고 뉴스기사에 들어가보도록 하겠습니다.
우선 제목들을 리스트에 저장을 따로 해두고
news_subject 스프객체에 .attrs함수를 사용해서 attribute들을 한 번 살펴보겠습니다.
news_subject = soup_response.find_all('a',{'class','news_tit'})
subject_list = []
for sub in news_subject:
subject_list.append(sub)
urls = news_subject
print(urls[0].attrs)href키에 대응하는 value에 주소가 있는것을 확인할 수 있습니다.

뉴스기사마다 url주소를 확인합니다.
urls = news_subject
for urls in soup_response.find_all('a',{'class','news_tit'}):
print(urls.attrs['href'])
이때 문제가 있습니다.
바로 url주소마다 각자 뉴스사의 이름이 들어가있어서 일정한 방식으로 url을 통해 각각의 뉴스기사에 접근할 수 없다는 것입니다.
하지만 네이버에서는 네이버뉴스라는 태그를 옆에 달고 있는 뉴스기사들이 있습니다. 이러한 뉴스들은 어떤가 살펴볼까요?
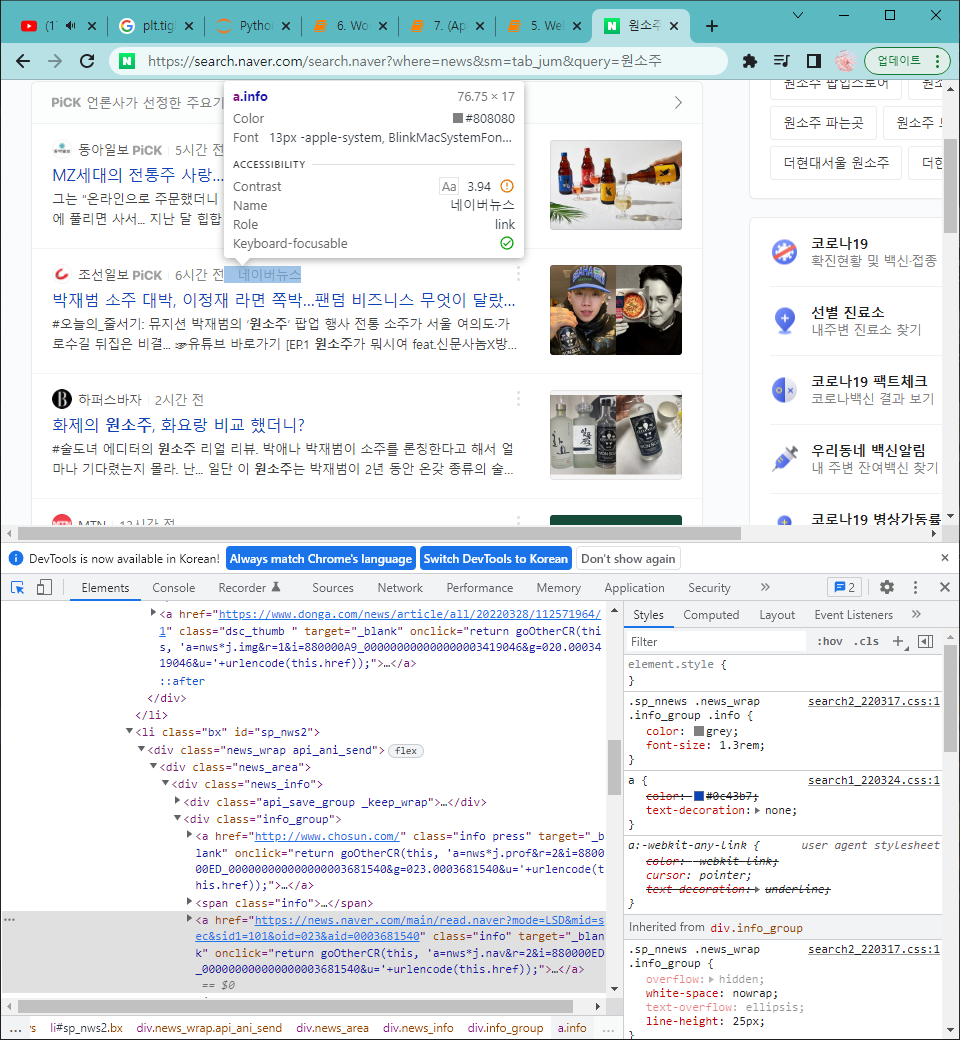
urls = news_subject
for urls in soup_response.find_all('a',{'class','info'}):
print(urls.attrs['href'])보시면 https://news.naver.com/이 포함되는 기사들이 공통적으로 등장하는 것을 볼 수 있습니다.
이러한 기사만 남길 수 있도록 startswith( )함수를 사용합니다.

urls_list = []
urls = news_subject
for urls in soup_response.find_all('a',{'class','info'}):
if urls.attrs['href'].startswith('https://news.naver.com/'):
urls_list.append(urls.attrs['href'])
print(urls_list)출력을 보면 다음과 같이 https://news.naver.com/이 포함된 url들만 있는것을 볼 수 있습니다.

02 단일 뉴스 페이지 분석
이제 뉴스페이지에 들어가서 뉴스 기사를 분석해보겠습니다.
urls_list에서 첫 번째 기사를 대상으로 진행했습니다.
headers를 추가해 준 이유는 Connection aborted 에러를 방지하기 위해서입니다. 이와 같은 에러는 다음과 같은 이유로 발생합니다.
- 코드로 보낸 요청을 서버에서 막을 때
- 요청을 빠르게, 많이 보내서 서버에서 공격으로 생각하고 막을 때
( User-Agent에 대해서 : https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
web_news = requests.get(urls_list[0], headers=headers).content
soup_news = BeautifulSoup(web_news,'html.parser')
02_01 제목
기사의 제목부터 알아보겠습니다.
마찬가지로 크롬 개발자 도구로 기사 제목을 확인해보면
<h3>태그에 id="articleTitle" 를 확인할 수 있습니다.
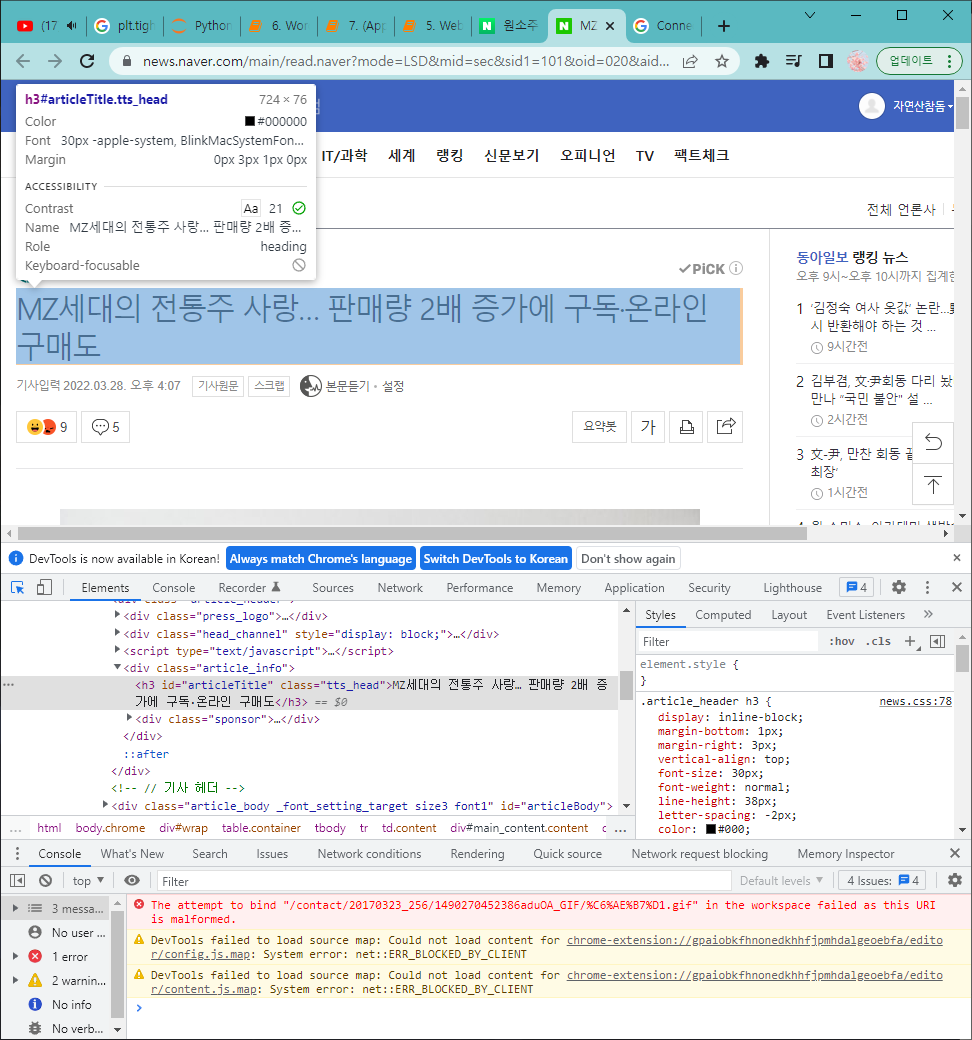
find( ) 함수로 제목을 확인해 보면 동일합니다.
title = soup_news.find('h3', {'id' : 'articleTitle'}).get_text()
print(title)
02_02 날짜
날짜도 마찬가지로 해봅니다.

날짜도 find( ) 함수로 확인해 봅니다.
date = soup_news.find('span', {'class' : 't11'}).get_text()
print(date)
02_03 본문
본문의 태그는 <div>, id = "articleBodyContents" 입니다.
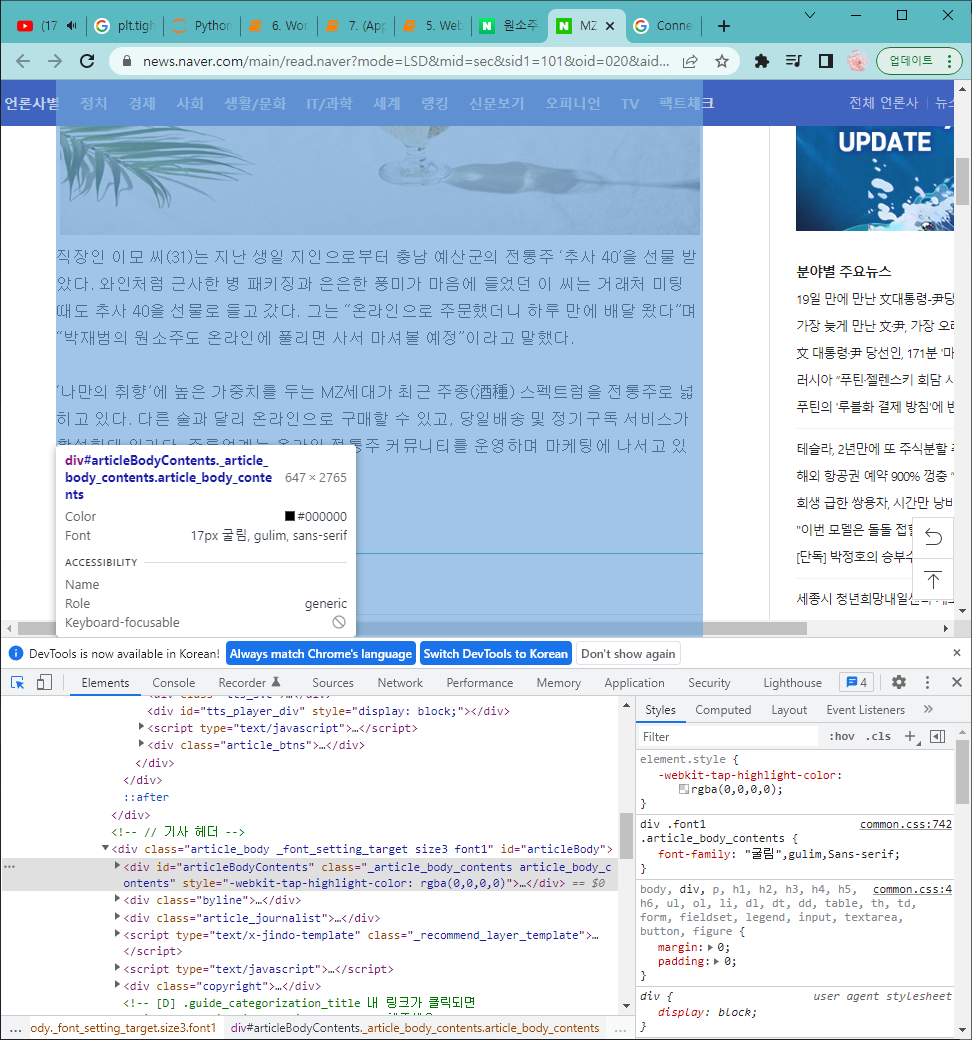
article_content = soup_news.find('div', {'id' : 'articleBodyContents'}).get_text()
print(article_content)
이때 본문의 내용과 함께 아래와 같은 내용을 함께 가져옵니다. 따라서 이를 replace( ) 함수로 지워주겠습니다.
// flash 오류를 우회하기 위한 함수 추가
function _flash_removeCallback() {}
article_content = article_content.replace('\n','')
article_content = article_content.replace('// flash 오류를 우회하기 위한 함수 추가function _flash_removeCallback() {}','')
print(article_content)이제 공백과 필요없는 내용이 지워진 본문이 출력됩니다.

02_04 언론사
언론사의 이름을 얻어보겠습니다. 이번에는 언론사의 이름이 있는 태그에 class나 id가 없으므로 부모태그를 이용해줍니다.
바로 위의 부모 태그를 보면 <address>태그에 class="address_cp" 입니다.
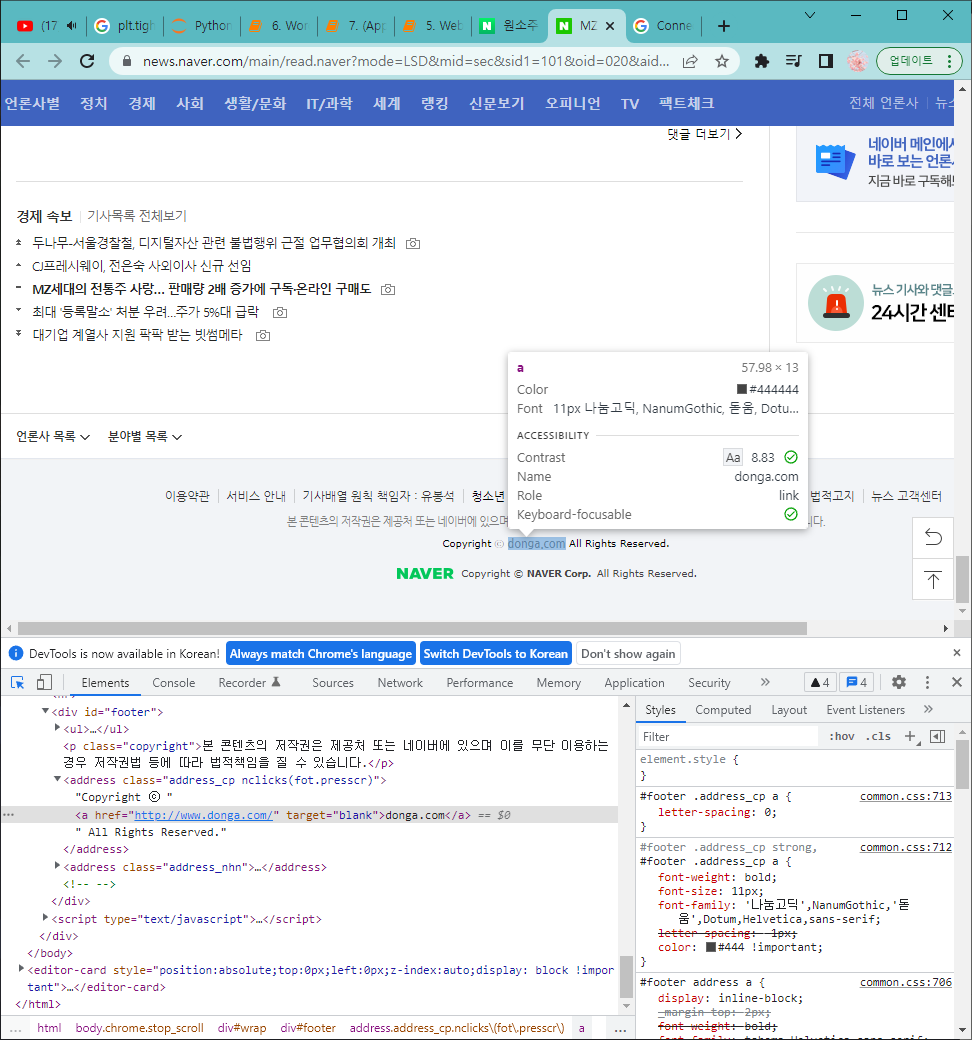
press_company = soup_news.find('address', {'class' : 'address_cp'}).find('a').get_text()
print(press_company)
03 여러 뉴스의 데이터 모으기
첫 번째로 여러개의 뉴스기사의 url을 얻었고 두 번째로 뉴스기사의 내용들도 분석해봤습니다.
그럼 이제 각각의 뉴스에 url로 접근해서 하나하나의 데이터들을 수집해보겠습니다!!
우선 각 기사들의 데이터를 종류별로 나눠담을 리스트를 생성합니다.
titles = []
dates = []
articles = []
article_urls = []
press_companies = []이제 위에서 작성했던 코드들을 for문을 이용해서 하나씩 기사를 돌려줍니다.
query = '원소주'
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=' + query
response = requests.get(url).content
soup_response = BeautifulSoup(response,'html.parser')
# 1) 네이버 뉴스만 추려내기
urls_list = []
for urls in soup_response.find_all('a',{'class','info'}):
if urls.attrs['href'].startswith('https://news.naver.com/'):
urls_list.append(urls.attrs['href'])
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
for url in urls_list:
news = requests.get(url, headers=headers).content
soup_news = BeautifulSoup(news,'html.parser')
# 2) 기사 제목
title = soup_news.find('h3', {'id' : 'articleTitle'}).get_text()
titles.append(title)
print('Processing article : {}', format(title))
# 3) 기사 날짜
date = soup_news.find('span', {'class' : 't11'}).get_text()
dates.append(date)
# 4) 기사 본문
article_content = soup_news.find('div', {'id' : 'articleBodyContents'}).get_text()
article_content = article_content.replace('\n','')
article_content = article_content.replace('// flash 오류를 우회하기 위한 함수 추가function _flash_removeCallback() {}','')
article_content = article_content.strip()
articles.append(article_content)
# 5) 기사 url
article_urls.append(url)
# 6) 기사 발행 언론사
press_company = soup_news.find('address', {'class' : 'address_cp'}).find('a').get_text()
press_companies.append(press_company)
이렇게 얻은 언론사들을 확인해보겠습니다.
print(press_companies)총 5개의 기사의 데이터를 얻은 것을 알 수 있습니다.

03_01 기사 날짜 형식 수정, 엑셀파일 저장
이제 datetime모듈로 날짜의 형식을 변경하고 pandas모듈로 수집한 데이터를 DataFrame객체로 만들고 이를 엑셀파일로 만들어줍니다.
article_df = pd.DataFrame({'Title' : titles,
'Date' : dates,
'Article' : articles,
'URL' : article_urls,
'PressCompany' : press_companies})
article_df.to_excel('result_{}.xlsx'.format(datetime.now().strftime('%y%m%d_%H%M')), index=False, encoding='utf-8')엑셀파일이 생성되고 내용이 잘 저장돼있는것을 확인 할 수 있습니다.

03_02 특정 뉴스 웹페이지 크롤링 중 에러 발생 시 회피 ( try except )
크롤링 중 특정 사이트에서 에러가 발생하는 경우에도 나머지 사이트의 데이터를 얻을 수 있도록 예외처리(try except)를 해줍니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
import re
titles = []
dates = []
articles = []
article_urls = []
press_companies = []
query = '원소주'
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=' + query
response = requests.get(url).content
soup_response = BeautifulSoup(response,'html.parser')
# 1) 네이버 뉴스만 추려내기
urls_list = []
for urls in soup_response.find_all('a',{'class','info'}):
if urls.attrs['href'].startswith('https://news.naver.com/'):
urls_list.append(urls.attrs['href'])
error_urls=[] # 에러난 사이트의 url을 담을 리스트
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
for url in urls_list:
try:
news = requests.get(url, headers=headers).content
soup_news = BeautifulSoup(news,'html.parser')
# 2) 기사 제목
title = soup_news.find('h3', {'id' : 'articleTitle'}).get_text()
print('Processing article : {}', format(title))
# 3) 기사 날짜
date = soup_news.find('span', {'class' : 't11'}).get_text()
# 4) 기사 본문
article_content = soup_news.find('div', {'id' : 'articleBodyContents'}).get_text()
article_content = article_content.replace('\n','')
article_content = article_content.replace('// flash 오류를 우회하기 위한 함수 추가function _flash_removeCallback() {}','')
article_content = article_content.strip()
# 5) 기사 발행 언론사
press_company = soup_news.find('address', {'class' : 'address_cp'}).find('a').get_text()
# 6) 위의 2~5를 통해 성공적으로 제목/날짜/본문/언론사 정보가 모두 추출되었을 때에만 리스트에 추가해 길이를 동일하게 유지합니다.
titles.append(title)
dates.append(date)
articles.append(article_content)
press_companies.append(press_company)
article_urls.append(url) # 6) 기사 URL
# 오류 발생시 오류메시지 출력 후 url을 리스트에 저장
except:
print('*** 다음 링크의 뉴스를 크롤링 중 에러 발생 : {} ***'.format(url))
error_urls.append(url)
article_df = pd.DataFrame({'Title' : titles,
'Date' : dates,
'Article' : articles,
'URL' : article_urls,
'PressCompany' : press_companies})
article_df.to_excel('result_{}.xlsx'.format(datetime.now().strftime('%y%m%d_%H%M')), index=False, encoding='utf-8')
print(article_df.head())
04 여러 페이지에 걸쳐 크롤링하기
네이버 뉴스 페이지의 하단의 페이지 번호를 바꿔가면서 url을 확인해 봅니다.

이때 발견할 수 있는 점이 바로 start파라미터의 전달인자가 1, 11, 21, 31 ... 로 변경된다는 것입니다.
즉 start=1 일때 1페이지, 11일때 2페이지, 21일때 3페이지... 라는 것을 알 수 있습니다.
아래의 캡처화면을 참고하세요!!


그럼 이제 start를 이용해서 페이지를 넘기면서 각각의 뉴스의 데이터들을 크롤링 하겠습니다.
(주소에서 필요없는 부분은 지워준 url을 사용했습니다.)
우선 start=21인 경우를 실험해 봅니다.
query = '원소주'
url = 'https://search.naver.com/search.naver?where=news&query=' + query + '&start=' + str(21)
response = requests.get(url).content
soup_news = BeautifulSoup(response, 'html.parser')
urls_list = []
for urls in soup_news.find_all('a',{'class','info'}):
if urls['href'].startswith('https://news.naver.com'):
urls_list.append(urls['href'])
for url in urls_list:
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
web_news = requests.get(url, headers=headers).content
source_news = BeautifulSoup(web_news, 'html.parser')
title = source_news.find('h3', {'id' : 'articleTitle'}).get_text()
titles.append(title)
print(title)
except:
print('*** 다음 링크의 뉴스를 크롤링하는 중 에러가 발생했습니다 : {}'.format(url))
뉴스페이지와 기사제목을 비교해보면 제목을 잘 추출한 것을 확인 할 수 있습니다.

이제 페이지를 자동으로 넘기면서 크롤링 하는 코드를 짜면 완성입니다.
while 문의 조건으로 입력한 페이지의 마지막 페이지인지를 검사하고 아닐 경우 끝에 +10을 해줍니다.
current_call = 1
last_call = (max_page - 1) * 10 + 1
while current_call <= last_call:
print(current_call) # 1, 11, 21, 31, 41
current_call += 10
04_01 최종 코드
드디어 최종코드 입니다.
원소주뉴스를 5페이지를 넘기며 네이버 뉴스의 기사를 크롤링하고 엑셀파일 저장하는 코드입니다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
titles = []
dates = []
articles = []
article_urls = []
press_companies = []
error_urls = []
query = '원소주'
max_page = 5
current_call = 1 # start의 전달인자
last_call = (max_page - 1) * 10 + 1 # 크롤링할 마지막 페이지의 start값
while current_call <= last_call:
print('\n{}번째 기사글부터 크롤링을 시작합니다.'.format(current_call))
url = 'https://search.naver.com/search.naver?where=news&query=' + query + '&start=' + str(current_call)
response = requests.get(url).content
soup_news = BeautifulSoup(response, 'html.parser')
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
urls_list = []
for urls in soup_news.find_all('a',{'class','info'}):
if urls['href'].startswith('https://news.naver.com'):
urls_list.append(urls['href'])
for url in urls_list:
try:
news = requests.get(url, headers=headers).content
soup_news = BeautifulSoup(news,'html.parser')
# 2) 기사 제목
title = soup_news.find('h3', {'id' : 'articleTitle'}).get_text()
print('Processing article : {}'.format(title))
# 3) 기사 날짜
date = soup_news.find('span', {'class' : 't11'}).get_text()
# 4) 기사 본문
article_content = soup_news.find('div', {'id' : 'articleBodyContents'}).get_text()
article_content = article_content.replace('\n','')
article_content = article_content.replace('// flash 오류를 우회하기 위한 함수 추가function _flash_removeCallback() {}','')
article_content = article_content.strip()
# 5) 기사 발행 언론사
press_company = soup_news.find('address', {'class' : 'address_cp'}).find('a').get_text()
# 6) 위의 2~5를 통해 성공적으로 제목/날짜/본문/언론사 정보가 모두 추출되었을 때에만 리스트에 추가해 길이를 동일하게 유지합니다.
titles.append(title)
dates.append(date)
articles.append(article_content)
press_companies.append(press_company)
article_urls.append(url) # 6) 기사 URL
# 오류 발생시 오류메시지 출력 후 url을 리스트에 저장
except:
print('*** 다음 링크의 뉴스를 크롤링 중 에러 발생 : {} ***'.format(url))
error_urls.append(url)
time.sleep(5)
current_call += 10 # 다음 페이지로 넘어간다
article_df = pd.DataFrame({'Title' : titles,
'Date' : dates,
'Article' : articles,
'URL' : article_urls,
'PressCompany' : press_companies})
article_df.to_excel('result_{}.xlsx'.format(datetime.now().strftime('%y%m%d_%H%M')), index=False, encoding='utf-8')
print(article_df.head())


'Programming Language > Python' 카테고리의 다른 글
| [Python] Wordcloud 만들기 (0) | 2022.03.29 |
|---|---|
| [Python] konlpy 한국어 텍스트 분석과 시각화 (4) | 2022.03.29 |
| [Python] TF-IDF, Cosine Similarity (0) | 2022.03.28 |
| [Python] 웹 크롤링 & 자연어 처리 (2) (0) | 2022.03.25 |
| [Python] 웹 크롤링 & 자연어 처리 (1) (0) | 2022.03.25 |



