
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 잡담
- SMTP
- ML
- 이것이 코딩 테스트다
- aof
- cuda
- 트러블슈팅
- nvcc
- semi-project
- 파일입출력
- nvidia-smi
- 크롤링
- category_encoders
- 인공지능
- selenium
- Trouble shooting
- AI
- 머신러닝
- Django
- PYTHON
- pandas
- json
- nvidia
- Roc curve
- 그리디
- Logistic linear
- auc
- EarlyStopping
- IOPub
- beautifulsoup
- Today
- Total
개발 블로그
[Python] 웹 크롤링 & 자연어 처리 (2) 본문

[Python] 웹 크롤링 & 자연어 처리 (1)에서 웹크롤링을 진행했다면 이번에는 자연어처리에 대해 정리하겠습니다.
지금 쓰고있는 두번째 게시물에 이어서 다음에 쓸 세번째 게시물에서 네이버 뉴스를 크롤링한 뒤 자연어 처리를 하는 것에 대해 포스팅 하겠습니다:)
목차>
00 The process of data analysis for data
- 텍스트 데이터를 str 자료형으로 준비
- Tokenize (형태소 분석)
- POS Tagging (Part-of-speech, 품사 표시)
- Stopwords 제거 (불용어 제거) -> 불용어 : 을, 를, 이, 가, 대명사, 전치사 등등
- 단어 갯수 카운팅 & 단어 사전 생성
- 단어 사전 기반 데이터 시각화
- 머신러닝/딥러닝 모델 적용
01 Preprocessing Text Data (Tokenize, POS, Stopwords, Lemmatize)
nltk는 텍스트 데이터 처리를 위한 패키지입니다.
Tokenize, POS, Stopwords, Lemmatize를 수행하기 위해 import해줍니다.
import nltkNLTK 자연어 처리 패키지 — 데이터 사이언스 스쿨
NLTK(Natural Language Toolkit) 패키지는 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지다. 다양한 기능 및 예제를 가지고 있으며 실무 및 연구에서도 많이 사용된다. NLTK 패키지가 제공
datascienceschool.net
01_01 tokenize( ), pos_tag( )
- nltk.word_tokenize( ) : 문장을 단어 수준에서 토큰화해 출력합니다.
- nltk.pos_tag( ) : 토큰화한 문장을 대상으로 품사를 태깅하여 출력합니다.
( 품사 태그 참고 : https://www.guru99.com/pos-tagging-chunking-nltk.html )
tokens = nltk.word_tokenize('Hello world!')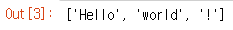
nltk.pos_tag(tokens)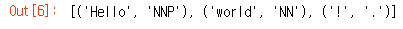
01_02 stopwords( )
- 영어의 불용어를 stopwords.words('english')로 출력할 수 있습니다.
- 총 불용어의 개수는 179개입니다.
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)
print(len(stop_words)) # 179
01_03 문장에서 stopwords제거하기
- sentence라는 예시 문자열에서 stopwords를 제거하기 위해 for문을 통해 형태소가 들어있는 리스트에서 형태소와 불용어를 비교하여 불용어가 아닌 경우 리스트에 추가해줍니다.
- 만약 추가 하고 싶은 불용어가 있다면 불용어 리스트에 append()함수를 사용하여 추가해 줍니다.
sentence = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
stop_words = stopwords.words("english") # stop_words == list
""" stopwords에 쉼표(,)와 마침표(.) 추가 """
stop_words.append(',')
stop_words.append('.')
result = []
for token in tokens:
if token.lower() not in stopWords: # 만약 소문자로 변환한 token이 stopWords 내에 없으면:
result.append(token) # token을 리스트에 더해준다
01_04 nltk.wordnet.WordNetLemmatizer()
- Lemmatization : 단어의 형태소적 & 사전적 분석을 통해 파생적 의미를 제거하고, 어근에 기반하여 기본 사전형 단어(표제어)인 lemma를 찾는 것.
- 눈으로 봤을 때는 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이는 것이 목적입니다.
# WordNetLemmatizer 객체 생성
lemmatizer = nltk.wordnet.WordNetLemmatizer()
# 복수를 단수로 리턴
print(lemmatizer.lemmatize("cats"))
# 비교급을 원형으로 리턴
print(lemmatizer.lemmatize("better", pos="a"))
# 과거형을 현재형으로 리턴
print(lemmatizer.lemmatize("ran", 'v'))- cats -> cat
- better -> good
- ran -> run
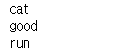
01_05 Lemmatization을 적용한 텍스트 분석
수업에서 제공해주신 moviereview.txt의 텍스트를 분석에 이용하였습니다.
위에서 진행했던 내용을 종합적으로 나타내면 아래와 같습니다.
lemmatizer = nltk.wordnet.WordNetLemmatizer()
stop_words = stopwords.words("english")
stop_words.append(',')
stop_words.append('.')
file = open('moviereview.txt','r',encoding = 'utf-8')
lines = file.readlines()
sentence = lines[1]
tokens = nltk.word_tokenize(sentence)
result = []
for token in tokens:
if token not in stop_words:
result.append(lemmatizer.lemmatize(token))
print(result)
02 Text Data Exploration & Visualization
우선 사전 준비를 위한 코드는 아래와 같습니다.
수업에서 제공해주신 영화 다크나이트의 리뷰가 담긴 텍스트파일 darkknight.txt를 사용했습니다.
- Counter클래스 참고 : [파이썬] collections 모듈의 Counter 클래스 사용법
import nltk
from nltk.corpus import stopwords
from collections import Counter
# 1) Stopwords 준비
stop_words = stopwords.words("english")
stop_words.append(',')
stop_words.append('.')
stop_words.append('’')
stop_words.append('”')
stop_words.append('—')
# 2) Text data 준비
file = open('darkknight.txt', 'r', encoding="utf-8")
lines = file.readlines()
# 3) Tokenizing
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized:
if token.lower() not in stop_words:
tokens.append(token)
02_01 가장 많이 등장하는 단어 추출하기 ( Counter.most_common( ) )
- 명사의 품사 태그들은 'NN', 'NNS', 'NNP', 'NNPS'들로 다 N(noun)으로 시작합니다.
따라서 startswith('N')함수를 사용하여 태그중에서 N으로 시작하는 태그를 가진 단어, 즉 명사만을 골라냅니다.
( 형용사라면 startswith('J'), 동사라면 startswith('V')를 사용합니다. ) - 그리고 Counter( )클래스를 이용하여 word_list의 Counter객체를 만듭니다.
- Counter객체의 most_common( )메서드를 사용하여 가장 많은 단어부터 내림차순으로 배열하고, 전달인자로 입력한 정수만큼 상위의 단어를 리턴합니다.
# 4) POS Tagging - 명사 종류만 모으기
tags = nltk.pos_tag(tokens)
word_list = []
for word, tag in tags:
if tag.startswith('N')
word_list.append(word.lower())
count = Counter(word_list)
print(count.most_common(10))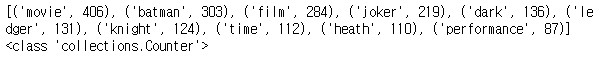
02_02 토큰 개수 확인하기 ( nltk.Text( ) )
nltk.Text( )는 문서를 편리하게 탐색할 수 있는 다양한 기능을 제공합니다.
# nltk.Text()의 객체타입
nltk.text.Textsample = nltk.Text(tokens_sample)
※ type(sample.tokens)은 list
- print(len(sample.tokens)) : returns number of tokens (document length)
- print(len(set(sample.tokens))) : returns number of unique tokens
- sample.vocab( ) : returns frequency distribution
file = open('darkknight.txt', 'r', encoding="utf-8")
lines = file.readlines()
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized:
if token.lower() not in stop_words:
tokens.append(token.lower())
# 말뭉치(corpus)는 자연어 분석 작업을 위해 만든 샘플 문서 집합을 말한다.
corpus = nltk.Text(tokens)
print(len(corpus.tokens))
print(len(set(corpus.tokens)))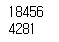
전체 토큰수는 18456
중복을 제거한 토큰수는 4281
즉, 4281개 종류의 단어가 사용된 텍스트 파일인 것을 유추할 수 있습니다.
02_03 토큰의 등장 횟수 시각화하기 ( 정규표현식, matplotlib )
- 정규표현식 참고블로그 : https://hamait.tistory.com/342
import matplotlib.pyplot as plt
import re
stop_words = stopwords.words("english")
stop_words.append('else')
file = open('darkknight.txt', 'r', encoding="utf-8")
lines = file.readlines()
tokens = []
for line in lines:
tokenized = nltk.word_tokenize(line)
for token in tokenized:
if token.lower() not in stop_words:
if re.match('^[a-zA-Z]+',token): # 정규표현식 적용(단어의 시작이 특수기호나 숫자가 아닌 경우)
tokens.append(token)
corpus = nltk.Text(tokens)
# 그래프로 시각화
plt.figure(figsize=(8, 3), dpi=100)
plt.title('Top 25words', fontsize=20)
corpus.plot(25)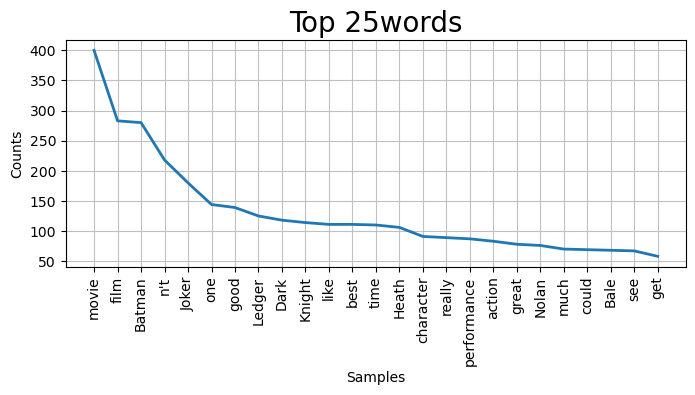
02_04 문맥 상 유사한 단어 출력하기 ( similar( ) )
위에서 구한 corpus에서 similar( )메서드를 사용하여 'batman'과 유사한 단어를 찾습니다.
similar( )메서드는 같은 문맥에서 주어진 단어 대신 사용된 횟수가 높은 단어들을 찾습니다.
corpus.similar('batman')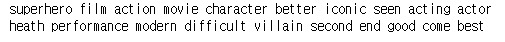
02_05 텍스트의 연어(collocation) 출력하기 ( collocations( ) )
위에서 구한 corpus에서 collocations( )메서드를 사용하여 연어를 찾습니다.
corpus.collocations() # 연어 리턴
'Programming Language > Python' 카테고리의 다른 글
| [Python] 웹 스크래핑 (1) (0) | 2022.03.29 |
|---|---|
| [Python] TF-IDF, Cosine Similarity (0) | 2022.03.28 |
| [Python] 웹 크롤링 & 자연어 처리 (1) (0) | 2022.03.25 |
| [Python] googlemaps를 사용해서 각 경찰서의 위도, 경도 정보를 얻기 (0) | 2022.03.24 |
| [Python] 데이터 시각화 (지도/ Folium, GeoJSON) (0) | 2022.03.24 |



