
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- json
- 머신러닝
- 크롤링
- ML
- IOPub
- Trouble shooting
- auc
- 트러블슈팅
- 잡담
- pandas
- semi-project
- selenium
- 파일입출력
- SMTP
- EarlyStopping
- stopwords
- Django
- AI
- PYTHON
- beautifulsoup
- find_all()
- pos_tag
- category_encoders
- 이것이 코딩 테스트다
- 인공지능
- 원소주
- Logistic linear
- 그리디
- aof
- Roc curve
- Today
- Total
목록AI (8)
개발 블로그
 EarlyStopping() 함수
EarlyStopping() 함수
NLP모델을 학습시키면서 fit함수를 보다가 callbacks란 파라미터에 EarlyStopping함수의 반환값을 주는 걸 보고 찾아보게 됐다. EarlyStopping 함수 과적합을 방지하기 위한 콜백함수 적절한 시점에 학습을 조기 종료시킨다. EarlyStopping 함수는 위 그림과 같이 validation_loss 의 값이 작아지다가 어느 순간 커질때가 있기 때문에 남은 epochs가 있어도 validation_loss가 가장 작은 순간에 학습을 일찍 종료시켜(Early Stopping) 최적의 모델을 저장하기 위한 함수이다. 위의 그래프를 보면 training_loss는 계속 줄어들지만 validation_loss는 줄어들다가 어느 순간 증가하게 된다. 이 뜻은 모델이 데이터를 지속적으로 학습하..
 Accuracy, Recall, Precision, F1 score에 대해서
Accuracy, Recall, Precision, F1 score에 대해서
분류 ML모델의 성능을 평가하기 위해 Accuracy, Recall, Precision, F1 score를 구하고 이를 기반으로 모델간의 성능을 비교하고 더 나은 지표를 얻기 위해 모델을 개선시켜 나갈 수 있습니다. 각각의 지표가 무엇을 의미하는지 알아보겠습니다. 우선 텍스트 데이터에 대해서 혐오표현인지 아닌지를 판별하는 모델이 있다고 가정하겠습니다. 만약 혐오표현이면 1, 혐오표현이 아니라면 0으로 라벨링합니다. 위 그림의 confusion matrix에서 각각 무엇을 뜻하는지는 아래와 같습니다. True Positive - 모델이 혐오표현이라고 예측하였고 실제로 그런 경우 True Negative - 모델이 혐오표현이 아니라고 예측하였고 실제로 그런 경우 False Positive - 모델이 혐오표현..
 Deep Learning이란?
Deep Learning이란?
AI SCHOOL 5기 강의를 진행하면서 드디어 메인파트라고 할 수 있는 딥러닝 파트 진도를 나가게 됐습니다. 딥러닝에 대한 정의부터 Tensorflow실습까지 진행하게 되어 기대가 됩니다. 딥러닝을 기반으로한 서비스를 만드는 프로젝트를 진행할텐데 벌써부터 설레네요ㅎㅎ 그럼 딥러닝에 대해 간단하게 짚어보는 글을 시작해보겠습니다. 01 딥러닝이란? 딥러닝(Deep Learning)이란 여러 층을 가진 인공신경망(Artificial Neural Network, ANN)을 사용하여 머신러닝 학습을 수행하는 것으로 심층학습이라고도 부릅니다. 따라서 딥러닝은 머신러닝과 전혀 다른 개념이 아니라 머신러닝의 한 종류라고 할 수 있습니다. (출처 : www.tcpschool.com/deep2018/deep2018_de..
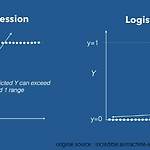 Logistic Regression & Cross-entropy function & ROC Curve, AUC
Logistic Regression & Cross-entropy function & ROC Curve, AUC
01 Logistic Regression 로지스틱 회귀(영어: logistic regression)는 영국의 통계학자인 D. R. Cox가 1958년에 제안한 확률 모델로서 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다. (출처 : https://ko.wikipedia.org/wiki/로지스틱_회귀) 머신러닝에서 로지스틱 회귀는 이진분류(binary classification) 문제를 해결하기 위한 모델입니다. ex) 스팸 메일 분류, 질병 양성/음성 분류, 신용카드 거래에서 정상 거래 및 이상 거래 분류 등... Sigmoid function을 이용하여 기본적으로 특정 Input data가 양성 class에 속할 확률을 계산 Sigmoid function의 정..
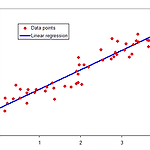 Linear Regression(선형 회귀) & Gradient Descent Algorithm(경사하강법)
Linear Regression(선형 회귀) & Gradient Descent Algorithm(경사하강법)
01 Linear Regression (선형 회귀) 종속 변수 y와 한 개 이상의 독립 변수 (또는 설명 변수)x 사이의 선형 상관 관계를 모델링하는 회귀분석 기법 : 정답이 있는 데이터의 추세를 잘 설명하는 선형 함수를 찾아 x에 대한 y를 예측 (선형 회귀 : https://wikidocs.net/21670) (선형 회귀wiki : https://ko.wikipedia.org/wiki/선형_회귀) 1개의 독립변수(x)가 1개의 종속변수(y)에 영향을 미칠 때 : 단순 회귀분석(Simple Regression Analysis) 2개 이상의 독립변수(x)가 1개의 종속변수(y)에 영향을 미칠 때 : 다중 회귀분석(Multivariate Regression Analysis) $$h\! _{\theta}=\..
 PCA ( Principal Component Analysis)
PCA ( Principal Component Analysis)
01 PCA (Principal Component Analysis ,주성분 분석) 주성분 분석은 고차원의 데이터를 저차원의 데이터로 환원시키는 기법을 말한다. 이 때 서로 연관 가능성이 있는 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간(주성분)의 표본으로 변환하기 위해 직교 변환을 사용한다. 데이터를 한개의 축으로 사상시켰을 때 그 분산이 가장 커지는 축을 첫 번째 주성분, 두 번째로 커지는 축을 두 번째 주성분으로 놓이도록 새로운 좌표계로 데이터를 선형 변환한다. (출처 : https://ko.wikipedia.org/wiki/주성분_분석) 차원 축소를 통해 최소 차원의 정보로 원래 차원의 정보를 모사(approximate)하는 알고리즘 차원 축소(Dimension Reduction) : 고..
 K-Means algorithm
K-Means algorithm
더보기 목차 01 K-Means algorithm k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이 알고리즘은 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다. (https://ko.wikipedia.org/wiki/K-평균_알고리즘) Algorithm K개의 임의의 중심값을 고른다. (보통 데이터 샘플 중의 하나를 선택) 각 데이터마다 중심값까지의 거리를 계산하여 가까운 중심값의 클러스터에 할당한다. 각 클러스터에 속한 데이터들의 평균값으로 각 중심값을 이동시킨다. 데이터에 대한 클러스터 할당이 변하지 않을 때까..
 인공지능과 머신러닝의 개념과 분류
인공지능과 머신러닝의 개념과 분류
목차> 더보기 목차 01 인공지능이란? Artificial intelligence (AI) is intelligence demonstrated by machines, as opposed to the natural intelligence displayed by animals including humans. Leading AI textbooks define the field as the study of "intelligent agents": any system that perceives its environment and takes actions that maximize its chance of achieving its goals. (original source : https://en.wikipedia.or..