
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PYTHON
- ML
- auc
- nvcc
- cuda
- Logistic linear
- Roc curve
- json
- nvidia
- 인공지능
- IOPub
- Django
- 잡담
- selenium
- pandas
- 그리디
- AI
- semi-project
- nvidia-smi
- 크롤링
- 이것이 코딩 테스트다
- category_encoders
- aof
- beautifulsoup
- SMTP
- 머신러닝
- EarlyStopping
- 파일입출력
- 트러블슈팅
- Trouble shooting
- Today
- Total
개발 블로그
인공지능과 머신러닝의 개념과 분류 본문

목차>
목차
01 인공지능이란?
Artificial intelligence (AI) is intelligence demonstrated by machines, as opposed to the natural intelligence displayed by animals including humans. Leading AI textbooks define the field as the study of "intelligent agents": any system that perceives its environment and takes actions that maximize its chance of achieving its goals.
(original source : https://en.wikipedia.org/wiki/Artificial_intelligence#Basics)
- 인공지능(AI) : 기계나 소프트웨어에 의해 보여지고 연출되는 지능
- 머신러닝(ML) : 명시적으로 프로그램 되어있지 않고 컴퓨터가 알아서 데이터로부터 학습하는 능력을 얻게하는 학문 분야. 주로 확률과 통계적 방법을 이용
- 딥러닝(Deep learning) : 머신러닝의 한 분야(하위 집합)로, 심층 신경망에 기반한 고수준의 추상화가 적용된 알고리즘의 집합을 아우르는 분야
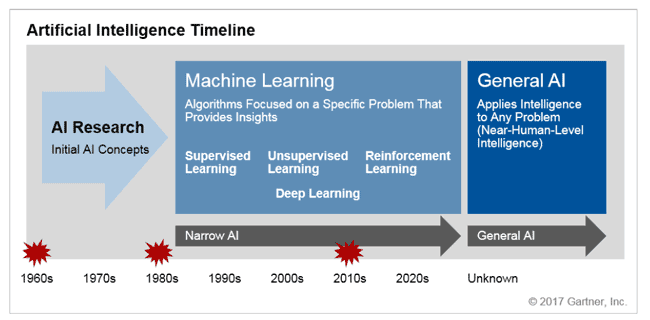
인공지능 발전의 3번의 wave
- 1st wave : 1956년 다트머스 대학의 Arthur Samuel의 checkers 문제. 영어를 러시아어로 번역하는 것이었는데 결과가 당시에는 저평가 되었다.
- 2nd wave : 1965년 DENDRAL, 1975년 PROSPECTOR, 1979년 MYCIN, 1989년 XCON 등의 지식 기반체계의 붐이 일어나면서 인공지능 연구가 활발히 진행되었다.
- 3rd wave : 3차 물결은 AI가 폭발적으로 성장한 시기로 컴퓨터 계산 연산 알고리즘의 발전과 GPU등의 자원 발전으로 이어졌다.
01_01 인공지능 모델(Model)이란?
인공지능 모델은 학습된 데이터와 학습 알고리즘으로 구성이 됩니다.
단일 모델에 대한 평가는 데이터 셋을 학습용 데이터, 테스트 데이터, 검증 데이터 형태로 구분하여 학습 알고리즘을 수행하고 AI모델의 성능을 평가하게 됩니다.
(출처 : http://aicerti.com/14 )
데이터에게 맞는 설명 방법을 찾는 과정 = 데이터를 가장 잘 표현하는 모델을 찾는 과정(= Model fitting)
Model의 종류 : 선형 함수, 비선형 함수, 확률 분포 함수, Neural Network의 Layer architecture & Parameter set 등
01_02 학습(Learning)이란?
- 내가 다루고 있는 데이터를 가장 잘 설명하는 방법을 찾는 과정
= 내 데이터에 맞는 모델을 찾는 과정 (= Model fitting)
데이터를 가장 잘 설명하는 모델을어떻게 찾을 것인가?
- 초기 모델(가설 모델)에 데이터를 넣는다.
- 결과를 평가한다. (예측/분류의 정확도 등 = mean squared error, classification error, recall & precision, etc.)
- 결과를 개선하기 위해 모델을 수정한다. (모델 내부의 Parameter 수정, 모델 종류의 변경 등)
= 실제 정답과예측 결과 사이의 오차(Loss, Cost, Error)를 줄여나가는 최적화 과정
02 머신러닝이란?
- A field of artificial intelligence that gives computers the ability to learn from data, without being explicitly programmed. (Arthur Samuel, 1959)
- A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measuredby P, improves with experience E. (Tom M. Mitchell, 1997)
- 어떠한 과제를 해결하는 과정에서
- 특정한 평가 기준을 바탕으로
- 학습의 경험을 쌓아나가는 프로그램
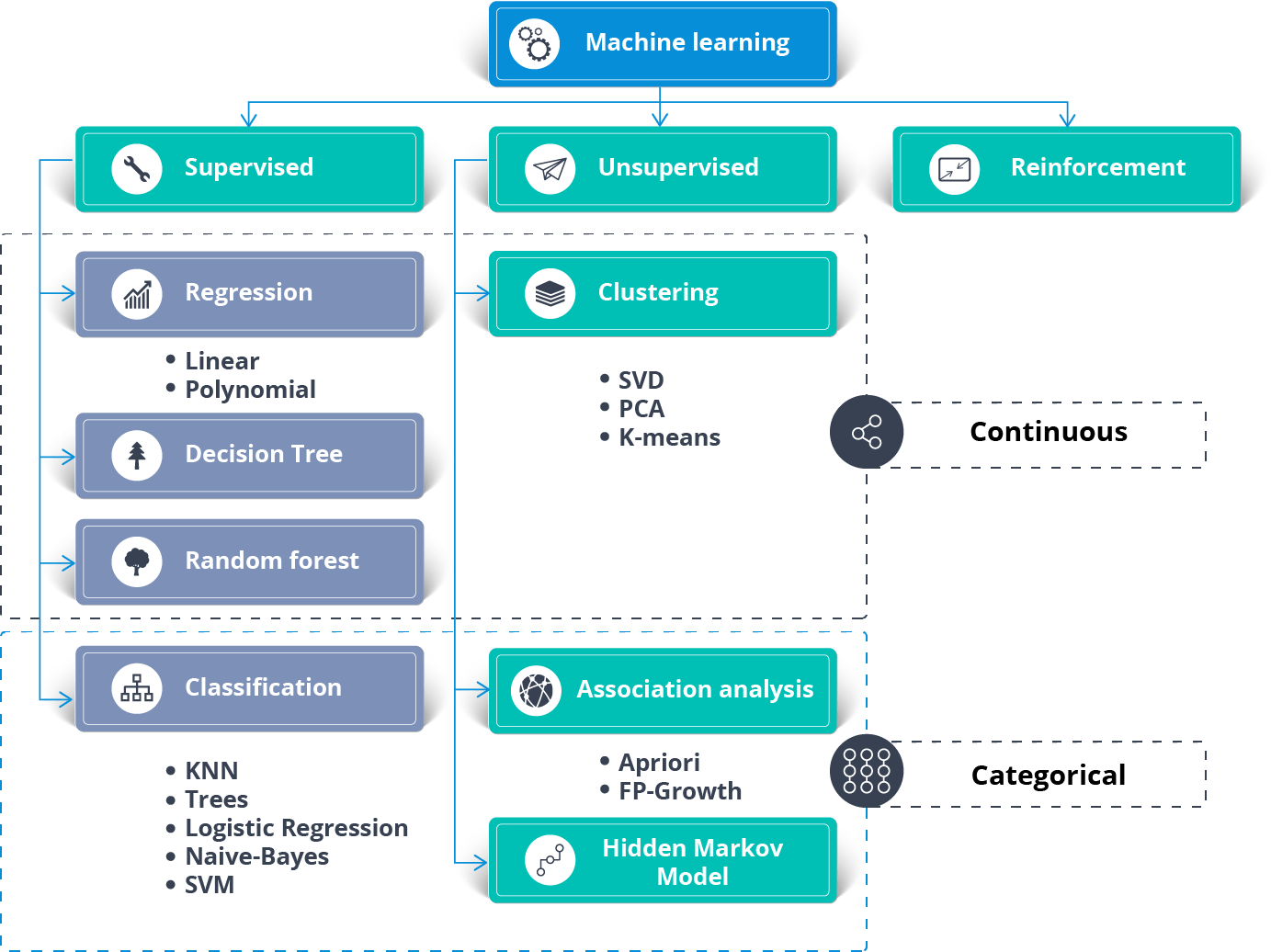
02_01 머신러닝의 분류
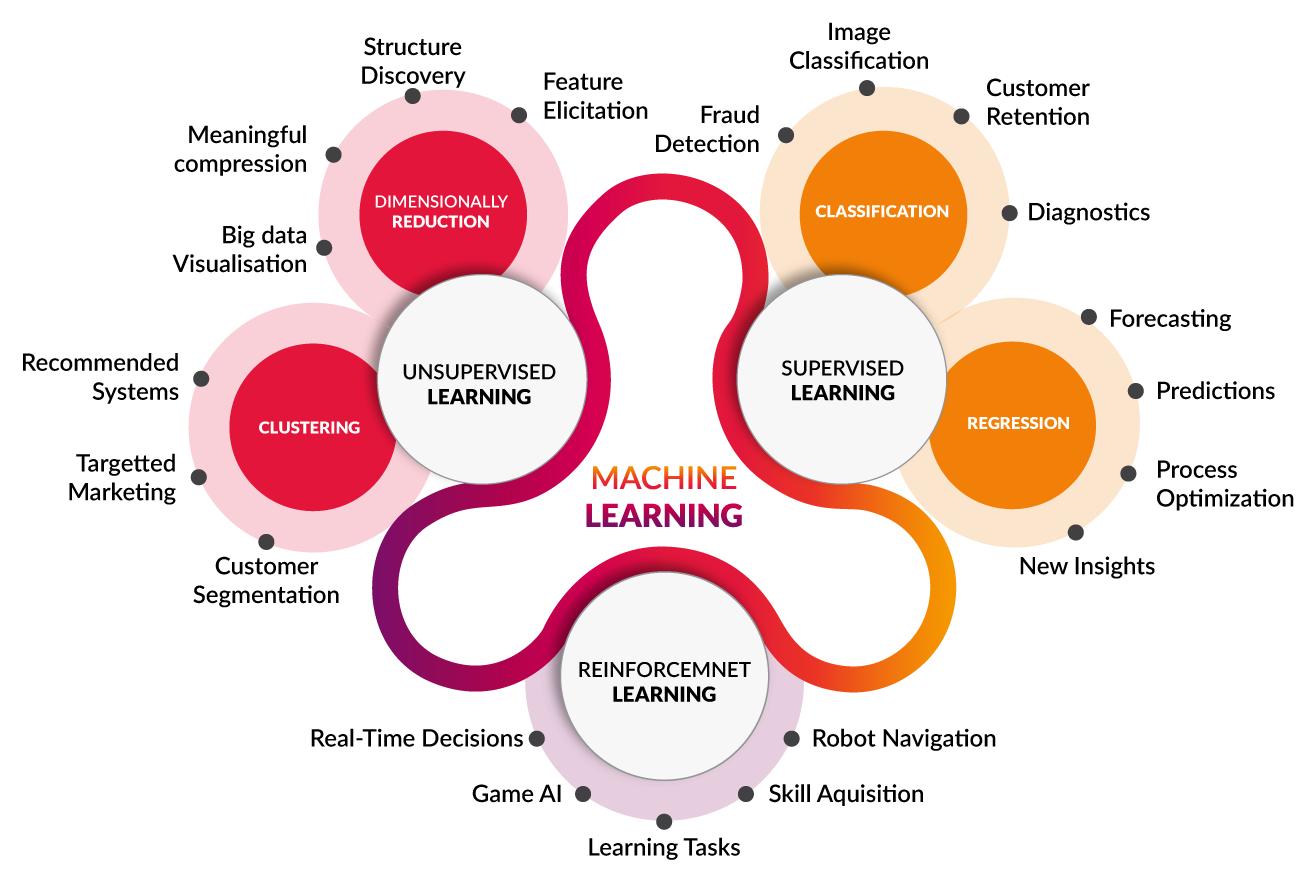
1) Supervised learning (지도 학습)
- Input data에 대한 정답을 예측하기 위해 학습 (→ Function approximator)
- 데이터에 정답(Label, Target)이 존재함
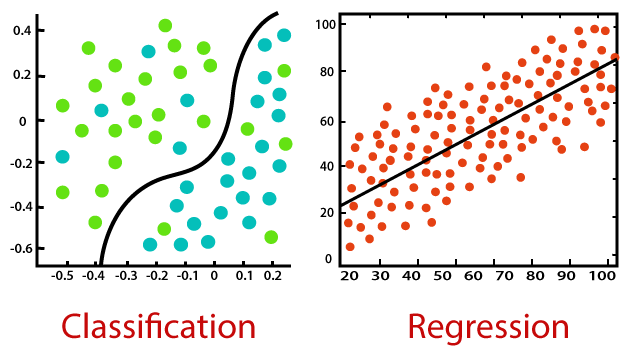
- Output의 형태에 따라 회귀 분석과 분류 분석으로 나눌 수 있음
회귀 Regression (Output이 실수 영역 전체에서 나타난다.)
분류 Classification (Output이 class에 해당하는 불연속값으로 나타남)
- 대표 알고리즘
: Linear/Logistic regression, Decision tree, Bayesian classification,
(Basic) Neural Network, Hidden Markov Model(HMM) 등
ex) 스팸 분류기, 주식 가격 예측, 유방암 진단, 이미지 인식 등
2) Unsupervised learning (비지도 학습)
- input data 속에 숨어있는 규칙성을 찾기 위해 학습 (→ (shorter) Description)
- 데이터에 정답(Label, Target)이 존재하지 않음
군집 분석 Clustering Algorithm
차원 축소 Dimensionality reduction (or Compression)
- 대표 알고리즘
: K-Means clustering, Nearest Neighbor Clustering, t-SNE, EM clusteringm, Principal component analysis (PCA),
Linear Discriminant Analysis (LDA) 등
ex) 고객군 분류(고객 세분화), 장바구니 분석(Association Rule), 추천 시스템 등
(강아지와 고양이가 무엇인지 알려주지 않고 여러 사진들을 보고 직접 비슷한 형태끼리 묶어보게 함)
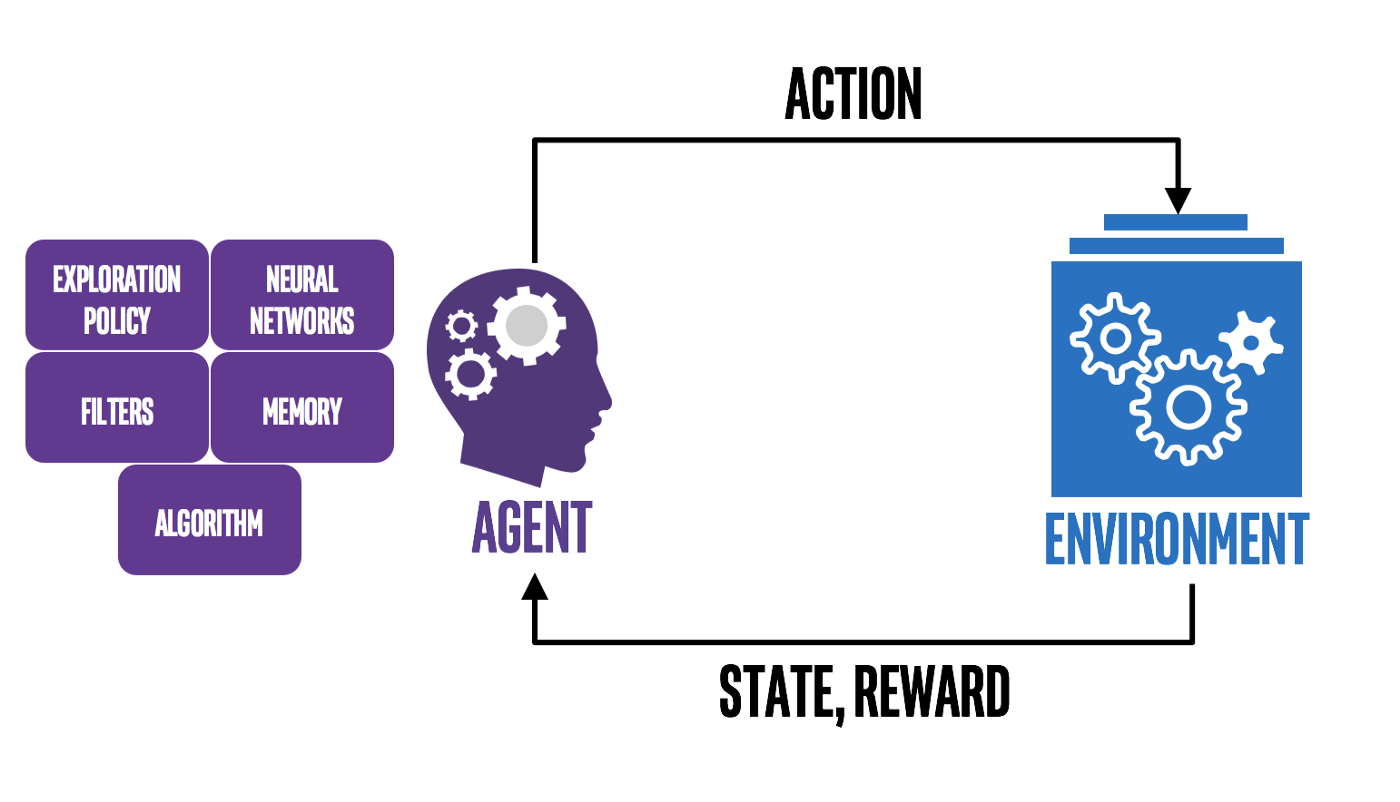
3) Reinforcement learning (강화 학습)
- Trial & Error 를 통한 학습 (→ Sequential decision making)
- 주위 환경과 자신의 행동(Decision) 사이의 반복적 상호작용을 바탕으로, 최종적으로 얻게 될 기대 보상을 최대화하기 위한 행동 선택 정책(Policy)을 학습
- 연속적인 단계 마다 상태(State)를 인식하고, 각 상태에 대해 결정한 행동(Action)들의 집합에 대해, 환경으로부터 받는 보상(Reward)을 학습하여, 전체 행동에 대한 보상을 최대화하는 행동 선택 정책(Policy)을 찾는 알고리즘
- 대표 알고리즘
: Monte Carlo methods, Markov Decision Processes, Q-learning, Deep Q-learning, Dynamic Programming 등
ex) 로봇 제어, 공정 최적화, Automated data augmentation 등
03 과적합(Overfitting)과 Generalization(일반화)
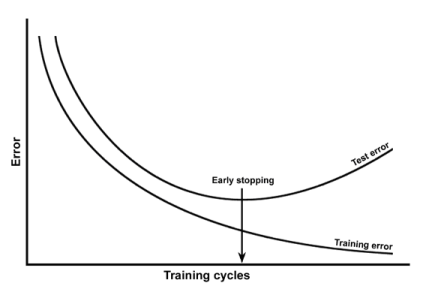
과적합(overfitting)은 기계 학습(machine learning)에서 학습 데이터를 과하게 학습(overfitting)하는 것을 뜻한다. 일반적으로 학습 데이타는 실제 데이터의 부분 집합이므로 학습데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
(출처: https://ko.wikipedia.org/wiki/과적합)
(과적합을 막는 방법들 : https://wikidocs.net/61374)
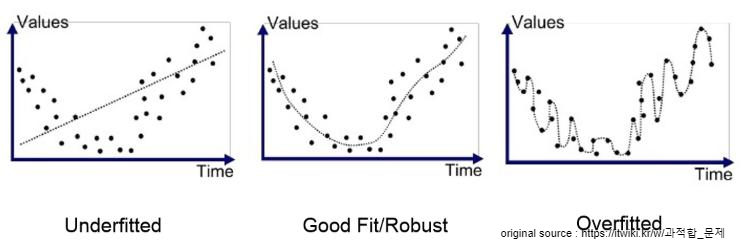
Capacity의 극대화 → Overfitting 발생 → Generalization error 증가 → 새로운 데이터에 자 대응하지 못함
03_01 Cross validation (CV, 교차 검증)
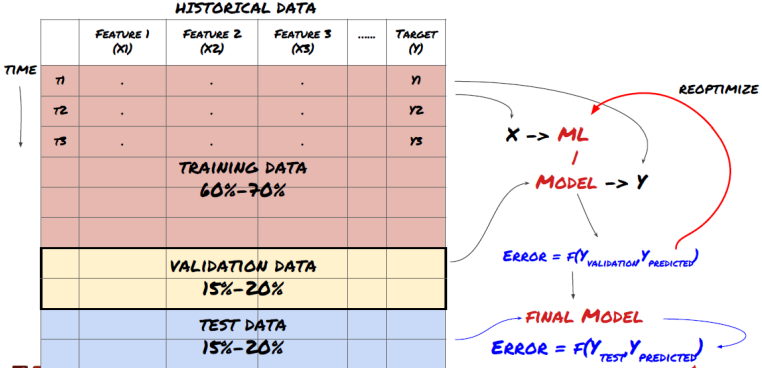
데이터를 3개의 그룹으로 나눈다.
- 60%의 Training data로 모델을 학습(Learn)시킨다.
- 20%의 Validation data로 모델(or Hyper Parameter)을 최적화/선택(Tune)한다.
- 20%의 Test data로 모델을 평가(Test only, no more tune)한다.
Validation & Test의 차이
- Validation : 여러 후보 모델 중 가장 좋은 결과를 내는 모델을 선택하는 과정
- Test : 선택한 모델의 실제 정확도를 평가하는 것
그 외 활용되는 방법들:
- (Stratified) K-Fold cross validation (후보 모델 간 비교 및 선택을 위한 알고리즘)
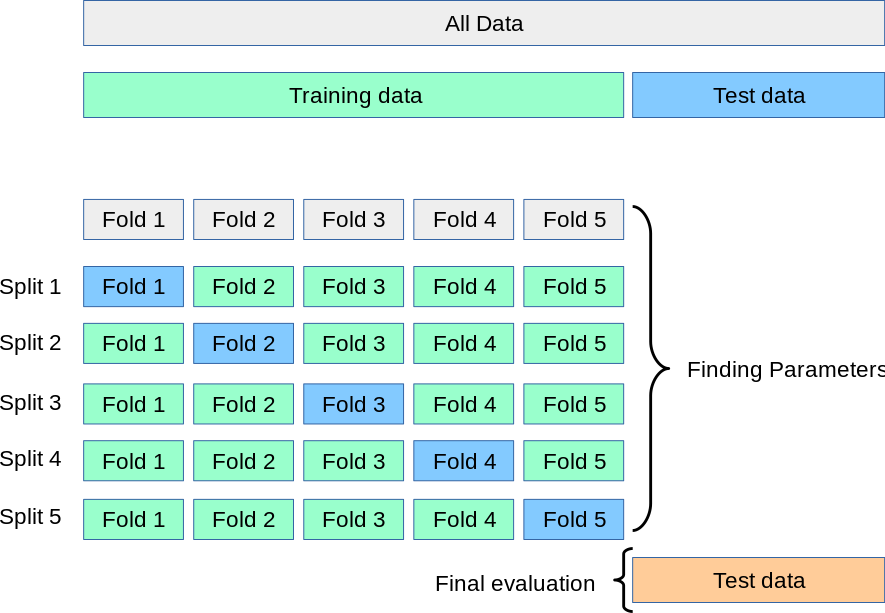
- Cost function에 Regulation term 추가 (L1 or L2, weight up = cost up)
- Drop-out & Batch Normalization 등
- Training data를 많이 확보하거나 모델의 Feature를 줄이는 것도 좋은 방법
<참고>
https://www.kaggle.com/code/marcovasquez/top-machine-learning-algorithms-beginner/notebook
✔️TOP Machine Learning Algorithms -Beginner💥
Explore and run machine learning code with Kaggle Notebooks | Using data from Iris Species
www.kaggle.com
'AI' 카테고리의 다른 글
| Deep Learning이란? (0) | 2022.04.27 |
|---|---|
| Logistic Regression & Cross-entropy function & ROC Curve, AUC (0) | 2022.04.24 |
| Linear Regression(선형 회귀) & Gradient Descent Algorithm(경사하강법) (0) | 2022.04.15 |
| PCA ( Principal Component Analysis) (0) | 2022.04.13 |
| K-Means algorithm (0) | 2022.04.13 |



